Multiple hypothesis testing
This article helps you:
Understand the differences between multiple hypothesis testing and single-hypothesis testing
Learn how Amplitude combats potential problems with multiple hypothesis testing
In an experiment, think of each variant or metric you include as its own hypothesis. For example, when you add a new variant, you put forth the hypothesis that changes you include in that variant should have a detectable impact on the experiment’s results.
The simplest experiments have only a single hypothesis. Single-hypothesis tests can yield valuable insights. However, it’s often more efficient or enlightening to include more than one metric or variant, or multiple hypotheses.
That said, multiple hypothesis testing has the potential to introduce errors into your calculations of statistical significance, through the multiple comparisons problem (also known as multiplicity or the look-elsewhere effect): The probability of making an error increases rapidly with the number of hypothesis tests you are running.
Problems with multiple hypotheses testing
For example, imagine you want to run an experiment around the color of your site’s “Buy now” button. Currently, it’s blue (making it the control), but you also want to test out green (variant #1) and purple (variant #2). If your false positive rate is 0.05 (5%) for each individual hypothesis test, the probability of finding a statistically significant result when the null hypothesis is true is:
1 - 0.95^2 = 0.0975
(This assumes the tests are independent.)
In other words, if you run enough tests, you eventually get a statistically significant result no matter what. With a 0.05 false positive rate, expect that one out of every 20 hypothesis tests are statistically significant by random chance alone.
The question asked by multiple hypothesis correction is, “is this stat sig result due to chance, or is it genuine?”
False positives
You may already be familiar with the idea of a false positive rate. It’s the ratio between:
- the amount of negative events falsely described as positive, and
- the total amount of actual negative events.
Every experiment carries the risk of a false positive result. This happens when an experiment reports a conclusive result in either direction, when there’s actually no real difference between variations.
The risk of a false positive result increases with each metric or variant you add to your experiment. This is true even though the false positive rate stays the same for each individual metric or variant.
Fortunately, there are statistical tools used to compensate and correct for the multiple comparisons problem. Amplitude uses the Bonferroni correction to do this.
Note
Bonferroni correction
The Bonferroni correction is the simplest statistical method for counteracting the multiple comparisons problem. It’s also one of the more conservative methods, and carries with it a greater risk of false negatives than other techniques. The Bonferroni correction doesn't, for example, consider the distribution of p-values across all comparisons, which we would consider to be uniform if the null hypothesis is true for all hypotheses.
The Bonferroni correction does, however, control for family-wise error rate and applies to the confidence interval. In the button color example above, dividing 0.1 by 2 equals .05, which is what we want. Thus, the family wise error rate (the probability of rejecting at least one hypothesis) is controlled.
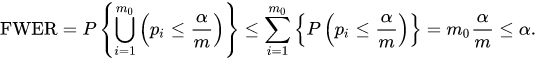
Note
Mathematically, the Bonferroni correction works by dividing the false positive rate by the number of hypothesis tests you are running; this is the same as multiplying the p-value by the number of hypothesis tests.
Amplitude Experiment performs Bonferroni corrections on both the number of treatments, and the number primary and secondary metrics:
- Bonferroni applies to the primary metric when there is more than one treatment.
- Bonferroni applies to the secondary metric if there are multiple secondary metrics or multiple treatments.
In either case, Amplitude places an info icon in the significance column when you apply Bonferroni correction. The tooltip shows the corrected and uncorrected p-value.
May 21st, 2024
Need help? Contact Support
Visit Amplitude.com
Have a look at the Amplitude Blog
Learn more at Amplitude Academy
© 2025 Amplitude, Inc. All rights reserved. Amplitude is a registered trademark of Amplitude, Inc.