
Agent Analytics
What’s the real impact of your AI agent?
Knowing your agent gave a good response is the easy part. Agent Analytics ties traces and evals to conversion, retention, and revenue, so you can connect agent quality to real business impact.
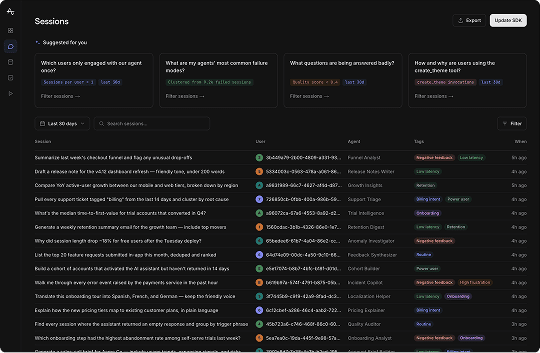
Sessions
Which users only engaged with our agent once?
What are my agents' most common failure modes?
What questions are being answered badly?
How and why are users using the create_theme tool?
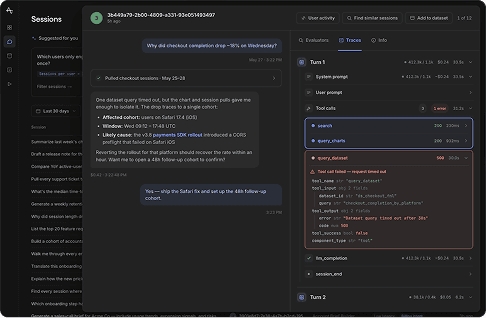
One dataset query timed out, but the chart and session pulls gave me enough to isolate it. The drop traces to a single cohort:
- Affected cohort: users on Safari 17.4 (iOS)
- Window: Wed 09:12 – 17:48 UTC
- Likely cause: the v3.8 payments SDK rollout introduced a CORS preflight that failed on Safari iOS
Reverting the rollout for that platform should recover the rate within an hour. Want me to open a 48h follow-up cohort to confirm?
When traditional analytics falls short
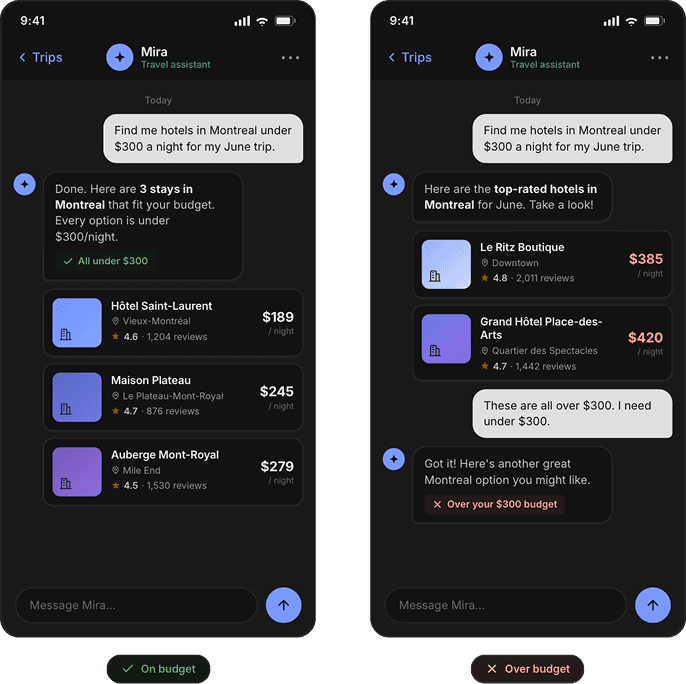
Most analytics tools were built for clicks and page views, not for reasoning and tool calls. Agents can hallucinate, ignore instructions, and confidently go off-track. All users who spend time with your agent look equally engaged. Who actually found it useful and came back?
Go beyond observability
Learn the product and revenue impact of your agents.
AI Quality
What the agent did
Product Outcomes
What the user did next
01 Observe
Inspect traces, prompts, tool calls, responses, latency, and cost. The raw record of what the agent actually did.
02 Evaluate
Score quality, intent, resolution, and failure modes. See where the agent helps, where it gets confused, and where it adds risk.
03 Decide
Tie those quality signals to conversion, retention, and revenue. Did the agent actually move the user forward?
04 Deploy
Tune prompts, run experiments, trigger guides, and personalize the next step from what you learned.
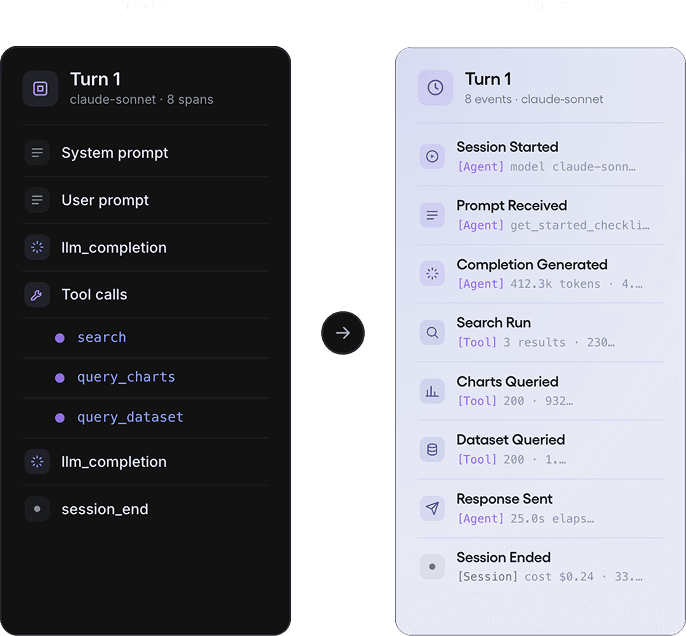
Trace turns automatically become Amplitude events
Each user message, tool call, and agent response is an Amplitude event with the same user_id as the rest of your product data. Unlike observability tools that stop at the trace, Agent Analytics decomposes these conversations into events, making them directly queryable in the same funnels, cohorts, and retention analyses you already use.
The questions you can finally answer
01
Did our model upgrade lift sign-up conversion this week, or hurt it?
02
What is the conversion delta when the agent answers correctly versus hallucinates?
03
Which agent topics correlate with expansion intent, and which ones with churn risk?
The Agent Analytics maturity model
Most observability tools stop at the lower levels of maturity. Agent Analytics takes you to the top by connecting AI quality to the user journey and revenue.
What is the AI worth in dollars?
How does AI usage affect the user journey?
What is the agent actually doing?
Did the agent do it correctly?
Can I see what happened?
Inside Agent Analytics
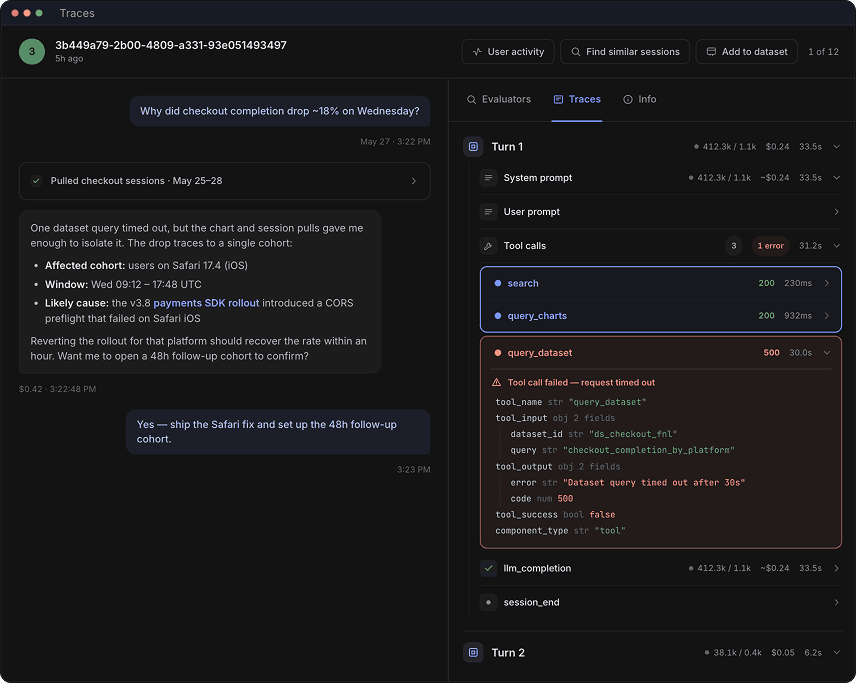
Production runs surprise teams with questions they never prepared the model for. Read the user prompt, the agent’s response, the tools it called, and the context it pulled, then jump straight to Session Replay to see what went wrong.
One dataset query timed out, but the chart and session pulls gave me enough to isolate it. The drop traces to a single cohort:
- Affected cohort: users on Safari 17.4 (iOS)
- Window: Wed 09:12 – 17:48 UTC
- Likely cause: the v3.8 payments SDK rollout introduced a CORS preflight that failed on Safari iOS
Reverting the rollout for that platform should recover the rate within an hour. Want me to open a 48h follow-up cohort to confirm?
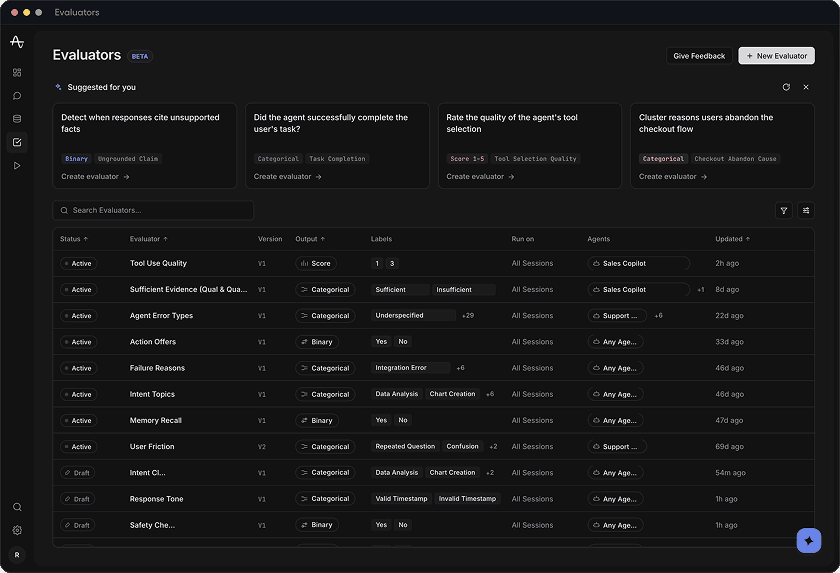
Evaluators
BETADetect when responses cite unsupported facts
Did the agent successfully complete the user's task?
Rate the quality of the agent's tool selection
Cluster reasons users abandon the checkout flow
Description
Grades every matching session for Tool Use Quality and writes the verdict back to the session as a property — available in charts, segments, and exports.
Grading prompt
Edit5 — fully correct, efficient, and well-justified
3 — partially correct or with minor issues
1 — incorrect, unsafe, or off-task
Weigh tool selection and reasoning, not just the final answer.
Label distribution · last 30 days
Configuration
Monitor
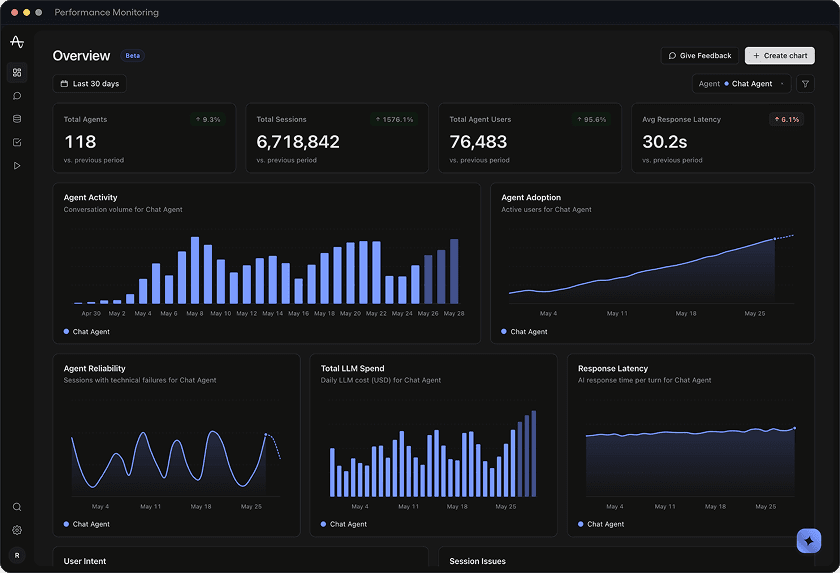
Last 30 daysChat AgentSearch…Agent Adoption
Active users for Chat Agent
Agent Activity
Conversation volume for Chat Agent
Failure Rate
Errored sessions for Chat Agent
Daily Spend
Inference cost for Chat Agent
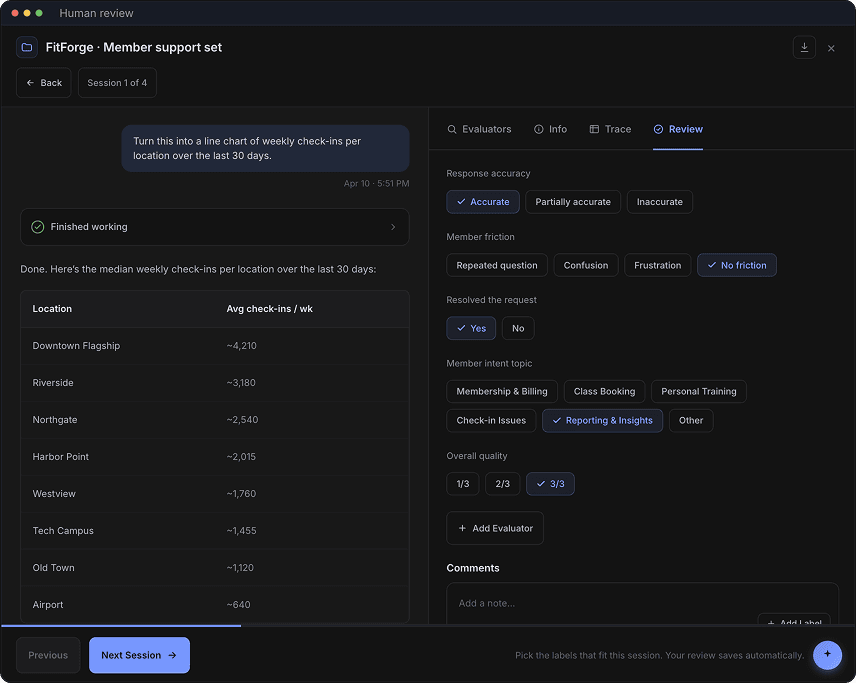
Done. Here’s the median weekly check-ins per location over the last 30 days:
Downtown Flagship and Riverside stand out — they drive 2–3x the check-ins of every other location. Worth a closer look at staffing and class capacity there.
View chart →Response accuracy
Member friction
Resolved the request
Member intent topic
Overall quality
Comments
We perfected it for ourselves
We shipped agents at Amplitude, hit the same issues you have, and built Agent Analytics as a result. Hear the data and stories from the team behind it.



Instrument any LLM provider
Native wrappers for the providers you actually use. An OpenTelemetry bridge for the rest. Manual capture when you want full control.
Python and Node, drop-in SDK, live in minutes.
Content-optional analytics
Purpose-built to let you control what leaves your environment.
Send full conversations, your own labels, or metadata only. Switch modes per agent or per event source.


Agent Analytics is in beta
Stop shipping on vibes
- Find the failure modes that actually cost you users.
- Measure conversion and retention by agent quality.
- Connect any trace to session replay and experiments.
Sign up for early access
Frequently asked questions
The analytics layer between LLM observability and product analytics. Every user message, tool call, agent response, and session end becomes an Amplitude event tagged with topic, quality score, and behavioral pattern, so you can build cohorts, funnels, and retention curves on AI session quality.
Tracing tools answer “What did the agent do?” Agent Analytics answers “Did it work for the user?” You can keep your tracing tool: AmplitudeGenAIExporter adds Amplitude as a second OpenTelemetry destination in one span processor registration.
No. The SDK has three privacy modes: metadata_only (tokens, latency, cost and behavioral signals only), customer_enriched (your own labels, no raw text) and full (managed enrichment). Most teams start in metadata-only and upgrade as trust builds.
Python on PyPI (pip install amplitude-ai) and Node.js / TypeScript on npm (npm install @amplitude/ai). Native wrappers for OpenAI, Anthropic, Gemini, Bedrock, Mistral, and Azure OpenAI. Framework integrations for LangChain, LlamaIndex, OpenAI Agents SDK, CrewAI, and the Claude Agent SDK. Anything emitting OpenTelemetry GenAI spans (OpenLIT, Traceloop, and OpenAI instrumentation) flows in via the bridge.
Every agent event carries a Session Replay ID. From any session in the explorer, View Replay opens at the moment the conversation started, so you watch the agent fail inside the actual product the user was using.
Each event carries the experiment variant as a property, so prompt A/B tests attribute correctly across multi-turn conversations. Quality scores and behavioral patterns flow into cohorts that Guides and Activation target in real time. Same workspace, same identity graph.
A new era of analytics
From a live agent overview to evals and datasets, every view ties what the agent did to what the user did next.
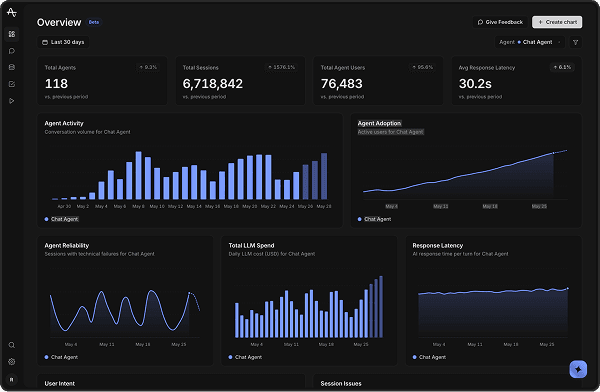
Overview
Beta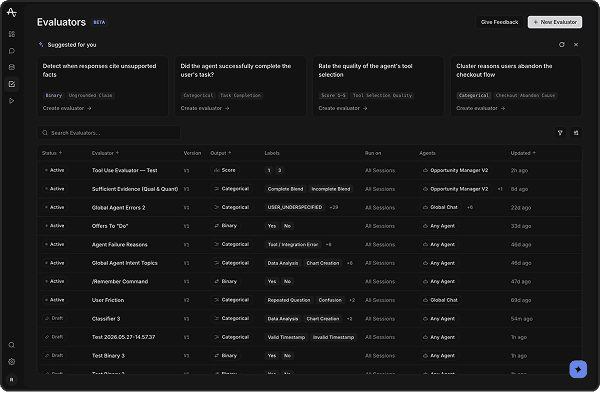
Evaluators
BETADetect when responses cite unsupported facts
Did the agent successfully complete the user's task?
Rate the quality of the agent's tool selection
Cluster reasons users abandon the checkout flow
Description
Grades every matching session for Tool Use Quality and writes the verdict back to the session as a property — available in charts, segments, and exports.
Grading prompt
Edit5 — fully correct, efficient, and well-justified
3 — partially correct or with minor issues
1 — incorrect, unsafe, or off-task
Weigh tool selection and reasoning, not just the final answer.
Label distribution · last 30 days
Configuration
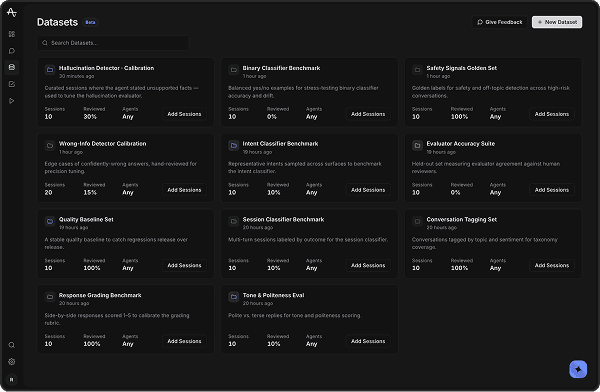
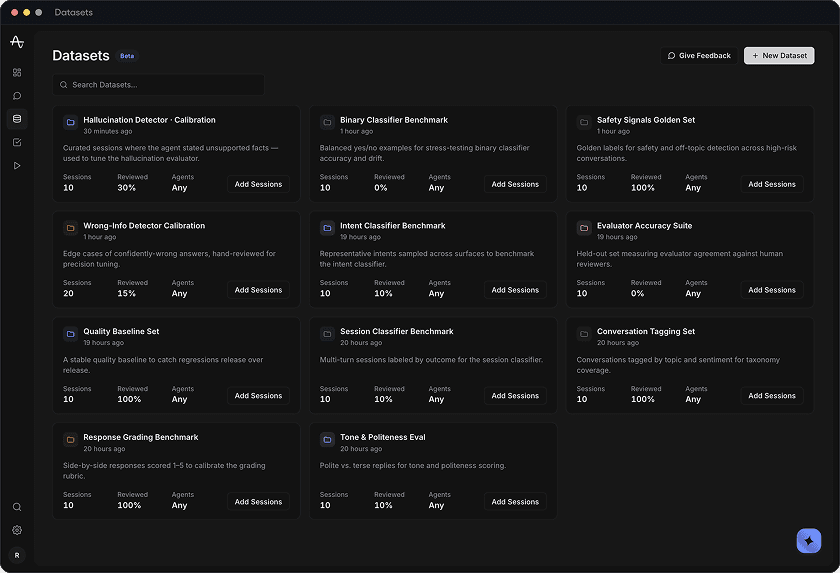
Datasets
BetaCurated sessions where the agent stated unsupported facts — used to tune the hallucination evaluator.
Balanced yes/no examples for stress-testing binary classifier accuracy and drift.
Golden labels for safety and off-topic detection across high-risk conversations.
Edge cases of confidently-wrong answers, hand-reviewed for precision tuning.
Representative intents sampled across surfaces to benchmark the intent classifier.
Held-out set measuring evaluator agreement against human reviewers.
A stable quality baseline to catch regressions release over release.
Multi-turn sessions labeled by outcome for the session classifier.
Conversations tagged by topic and sentiment for taxonomy coverage.
Sessions
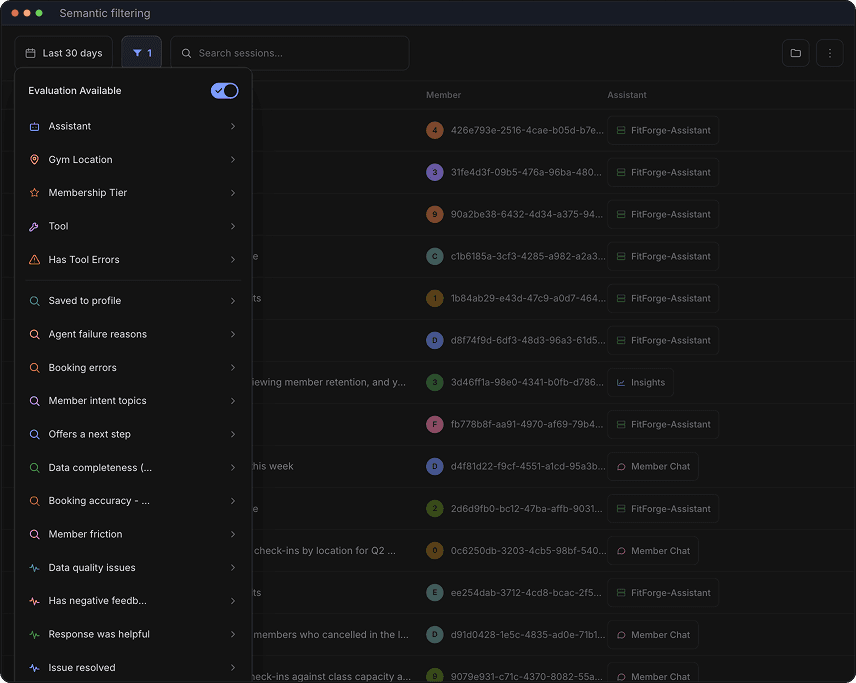
Which users only engaged with our agent once?
What are my agents' most common failure modes?
What questions are being answered badly?
How and why are users using the create_theme tool?