

*Contributing authors: Scott Kramer, Bilal Mahmood, Bill Pentney, Eric Pollmann, Jeffrey Wang *
has traditionally and primarily been about observing the past: count the number of sign-ups since last Monday; observe how many of those users purchase on Tuesday; measure their retention by Wednesday.
Product teams do these measurements in the past so that they can influence the future: forecast how many users will sign up next week; estimate user affinity to make their first purchase; predict who has the highest risk of churn.
Answering these questions accurately and with certainty is the difference between product analytics and . When teams have access to , they can make the decisions, build the features, and run the marketing campaigns that generate more customer and business value.
Unfortunately, predicting future outcomes at scale, in a self-serve and real-time modality, requires significant investment in distributed systems and machine learning architecture.
That is, unless you’re an Amplitude customer. To help our customers operate with product intelligence and gain access to predictive insights, we built an automated machine learning (AutoML) system into Amplitude’s proprietary data ecosystem, . With this enhanced version of Nova, Amplitude customers can generate predictive insights at scale.
For early access to predictive insights powered by Nova AutoML, .
Developing a Machine Learning Model: How We Built AutoML into Nova
Our work to deliver AutoML at scale began with our this spring. From there, our engineering team worked to integrate Clearbrain’s technology into Nova and automate the four stages of a for our customers.
How Traditional Machine Learning Workflows Work
Developing a Machine Learning model is an iterative cycle of project definition, data transformation, training and deployment.
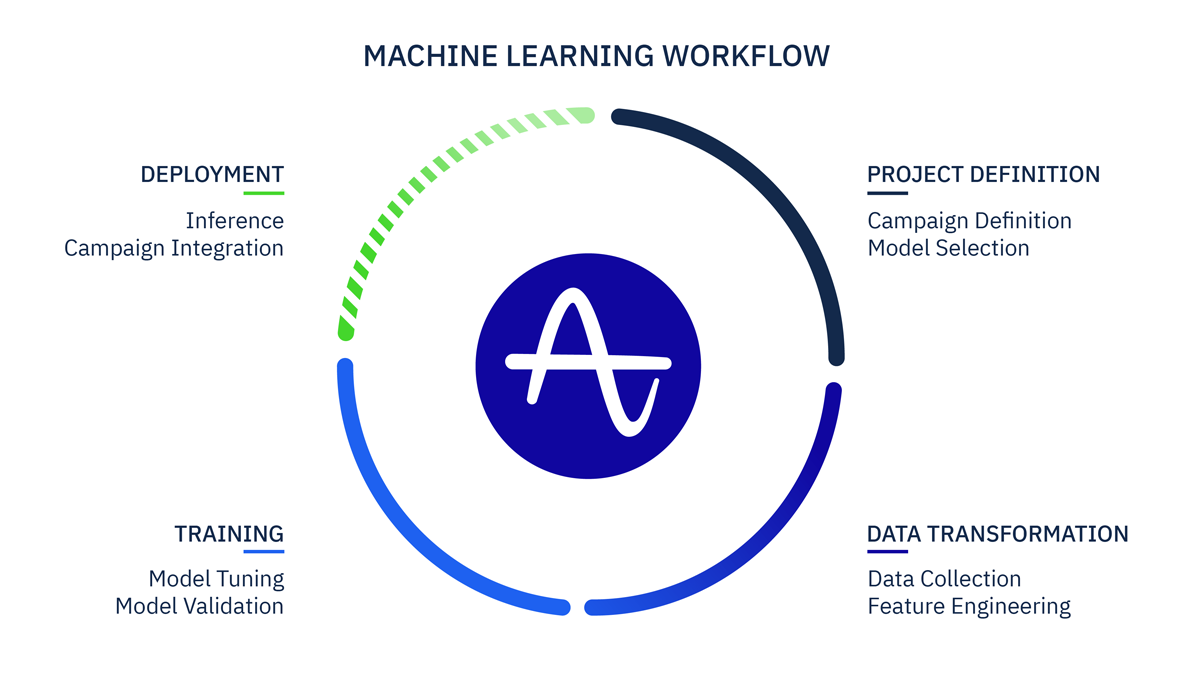
1. Project Definition
The first step to developing a machine learning model is understanding the question being asked and what will be done with the answers. Developing a lifetime value (LTV) prediction system or a could require different ML models depending on the needs of the use case. Researching the applicable problem space and becoming familiar with different ML models is an additional challenge in creating an AutoML system.
2. Data Transformation
The second step is data transformation. Models learn from historical data just like people do. Collecting high signal data and persisting it in the right format to support machine learning models is challenging. Not only do the models need data in the , but solving other common data processing issues—such as event and user deduplication and normalization—can make starting from scratch a grueling task. Auto ML requires ingesting data from many different sources and persisting it in a consistent format.
3. Training
After data transformation comes model training, the process of teaching the model to predict future outcomes given historical data. Validating that the model can predict well after training and tuning it to predict better are the challenging parts of this step. This step is a significant challenge for Auto ML because the generic tuning parameters must perform well for many predictions and customer data types, without human intervention.
4. Deployment
The final step in an ML workflow is deployment. Here the trained mathematical model is applied to current data and outputs scores. Auto ML systems must be able to scale predictive calculations horizontally—supporting many predictions across millions of user records. The fresh predictive scores must serialize quickly to endpoints or services where they can then be leveraged for the desired use case.
Traditionally this workflow would require teams of engineers and data scientists collaborating over weeks to build just one model. Nova’s new AutoML system instead accelerates this process to work on any dataset in minutes, addressing each key challenge through proprietary new architecture.
How We Automated the Traditional Machine Learning Workflow
Our team built the Nova AutoML system to automate the four stages of a traditional ML workflow. This work involved connecting a real-time datastore to a distributing computing system to a model deployment managed service. These are the main technologies supporting the Nova AutoML system:
Nova Query: is the distributed real-time datastore that serves queries over our customers’ event data and user property data, based on our . The AutoML system leverages Nova as the backbone for the machine learning pipeline. It uses Nova Query’s real-time data querying capabilities to transform events into machine readable user aggregates, leveraging Nova Query’s functionality to label the model’s input and target outcomes, and persisting the results of inference for querying through Amplitude. Nova was the effective difference in enabling the real-time extensibility of this system.
Nova AutoML Technology Overview
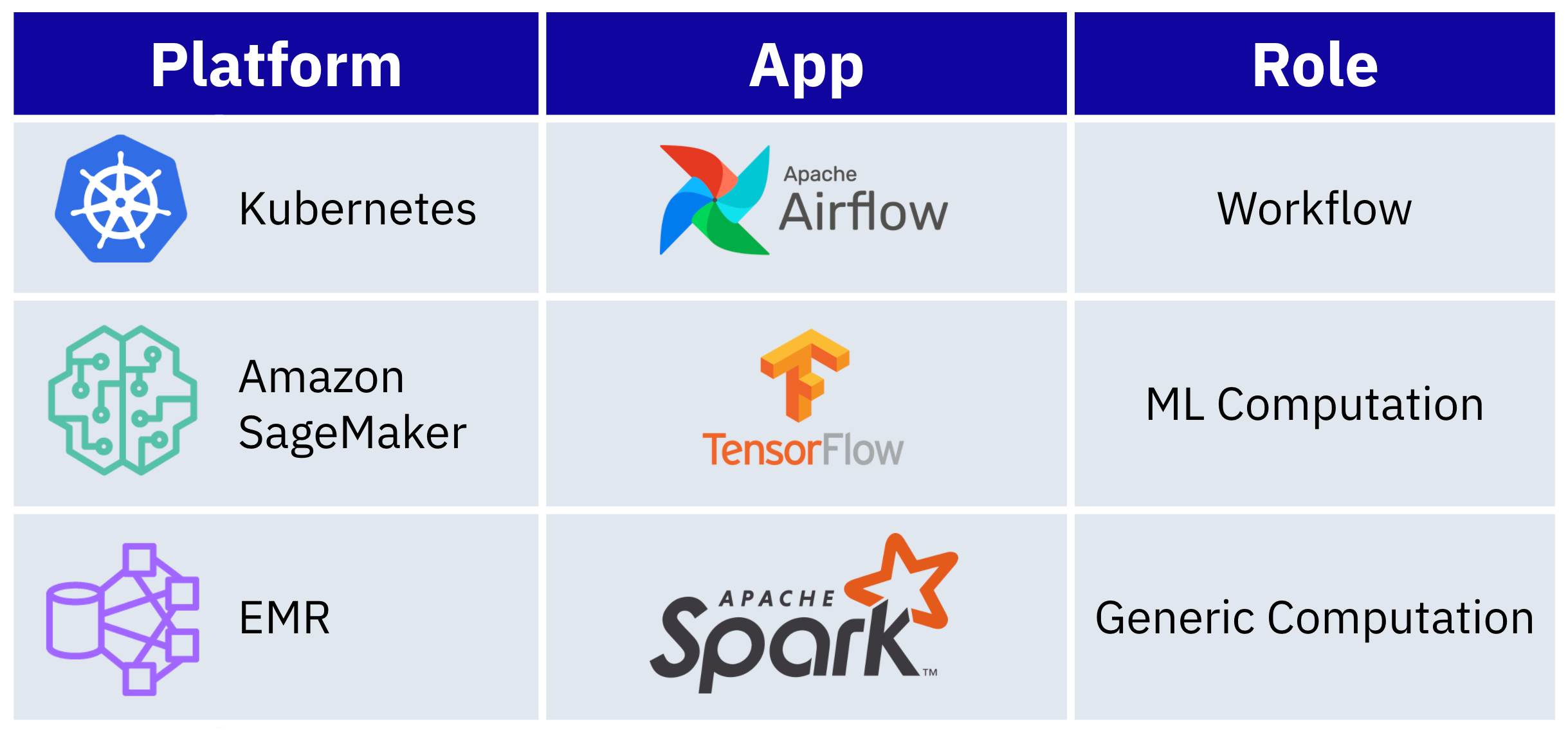
These are the relationships among the platforms and applications in Nova AutoML and what role they serve in the system.
Apache Spark: is the unified analytics engine that helps scale various steps of our ML pipeline. Running on for package management and autoscaling, Spark powers the distributed computing component of our Nova AutoML system to run arbitrary data processing on top of the transformed data outputted by Nova Query. Specifically, Spark enabled us to run distributed computations over tens of gigabytes of data, scaling the generation of our user feature vectors used in model training.
Amazon SageMaker: For facilitation of the training and inference portions of our AutoML system, we leveraged . SageMaker’s Jobs feature enabled us to run Tensorflow and SKLearn transforms at high levels of computation during the model training components, while managing autoscaling and batch processing of the inference stages. The out-of-the-box monitoring capabilities also allowed us to quickly iterate on testing and parameterization of our modeling infrastructure.
Apache Airflow: Coordinating all of the interconnected processes among Nova Query, Spark, and SageMaker was . Airflow is a workflow hosting, scheduling, and management platform, facilitating the training and inference pipelines to run tasks on remote systems that require varying memory or compute throughout the AutoML system.
How the Automated Machine Learning System Works
The combination of Nova Query with Spark and SageMaker, all orchestrated through Airflow, is what enables Nova AutoML to deliver self-serve predictive insights.
To start, the AutoML system initializes when a customer indicates in the Amplitude UI that they want to run a predictive analysis. Immediately, an Airflow training pipeline initiates a series of data transformation steps (also known as feature engineering) from the customer’s raw event data stored in Nova Query.
Training Pipeline Workflow
The training pipeline queries Nova Query for the feature matrix inputs, post-processes the results in Spark and then trains the model via TensorFlow.
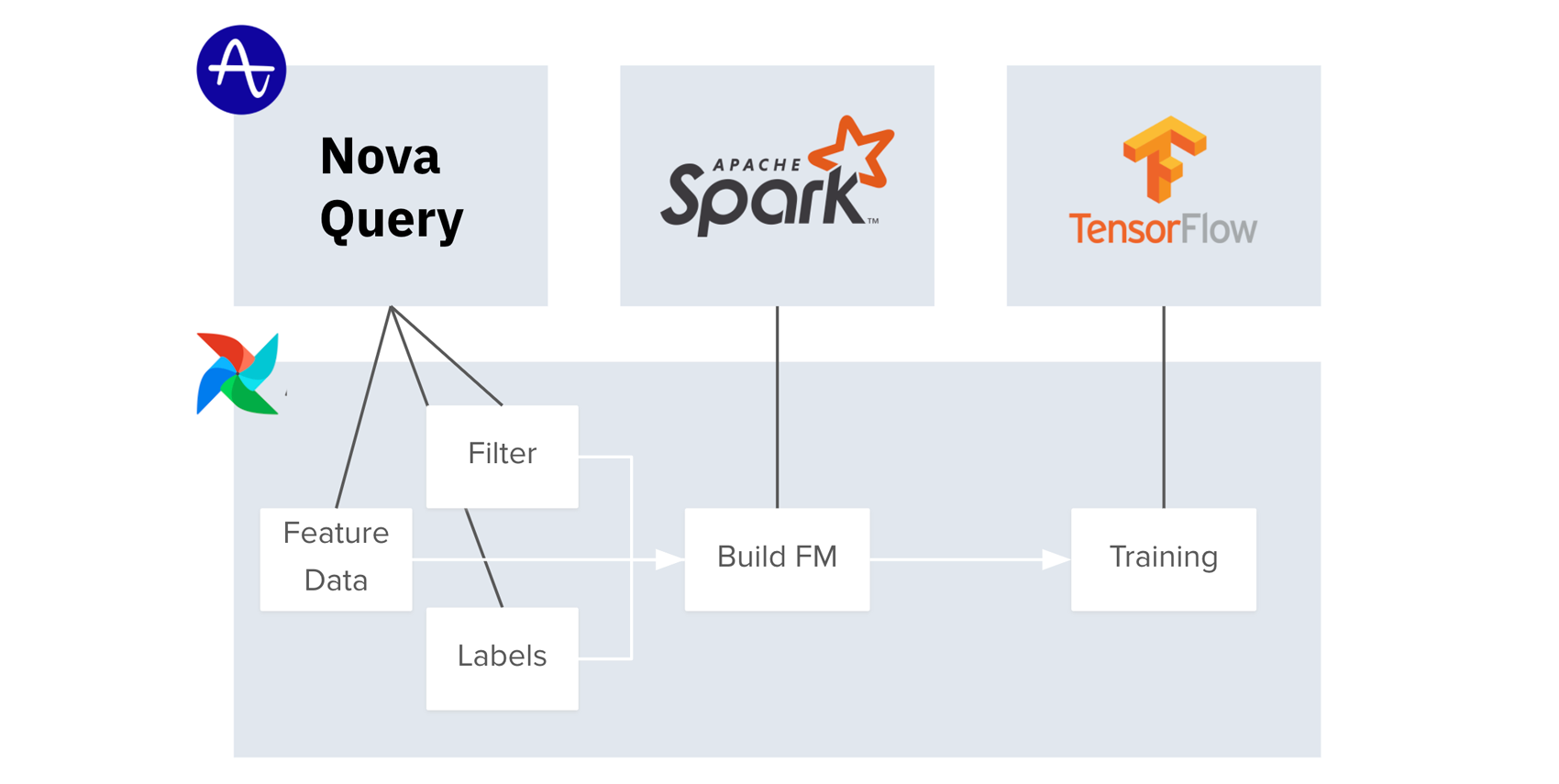
The feature engineering processes are built entirely off of three real-time data queries run on Nova Query. The first query generates the user feature aggregates that serve as input variables into the training algorithm. The second query constructs the labels for the training algorithm that indicate whether a specific user has or has not performed the desired outcome in the past. And the third query filters the set of users, or starting cohort, that will be selected for training the algorithm. Nova Query writes out all these queries into parquet files to ensure post-processing on a columnar basis.
Next, our Spark cluster is employed to post-process each of the three feature vectors produced by Nova Query into a machine readable format, and scalably join all three vectors into a single feature matrix. The feature matrix is output to Amazon Simple Storage Service (Amazon S3) as a protobuf—a row based format—so that when Nova AutoML proceeds to model training, Tensorflow can stream user vectors individually.
The Airflow system then initiates a formal model training pipeline in SageMaker, loading the feature matrix, training a predictive model, and writing the model back out to Amazon S3.
Inference Pipeline Workflow
The inference pipeline queries Nova Query for feature matrix input, post processes that data in Spark, runs inference on Tensorflow and then writes predictive scores back into Nova Query.
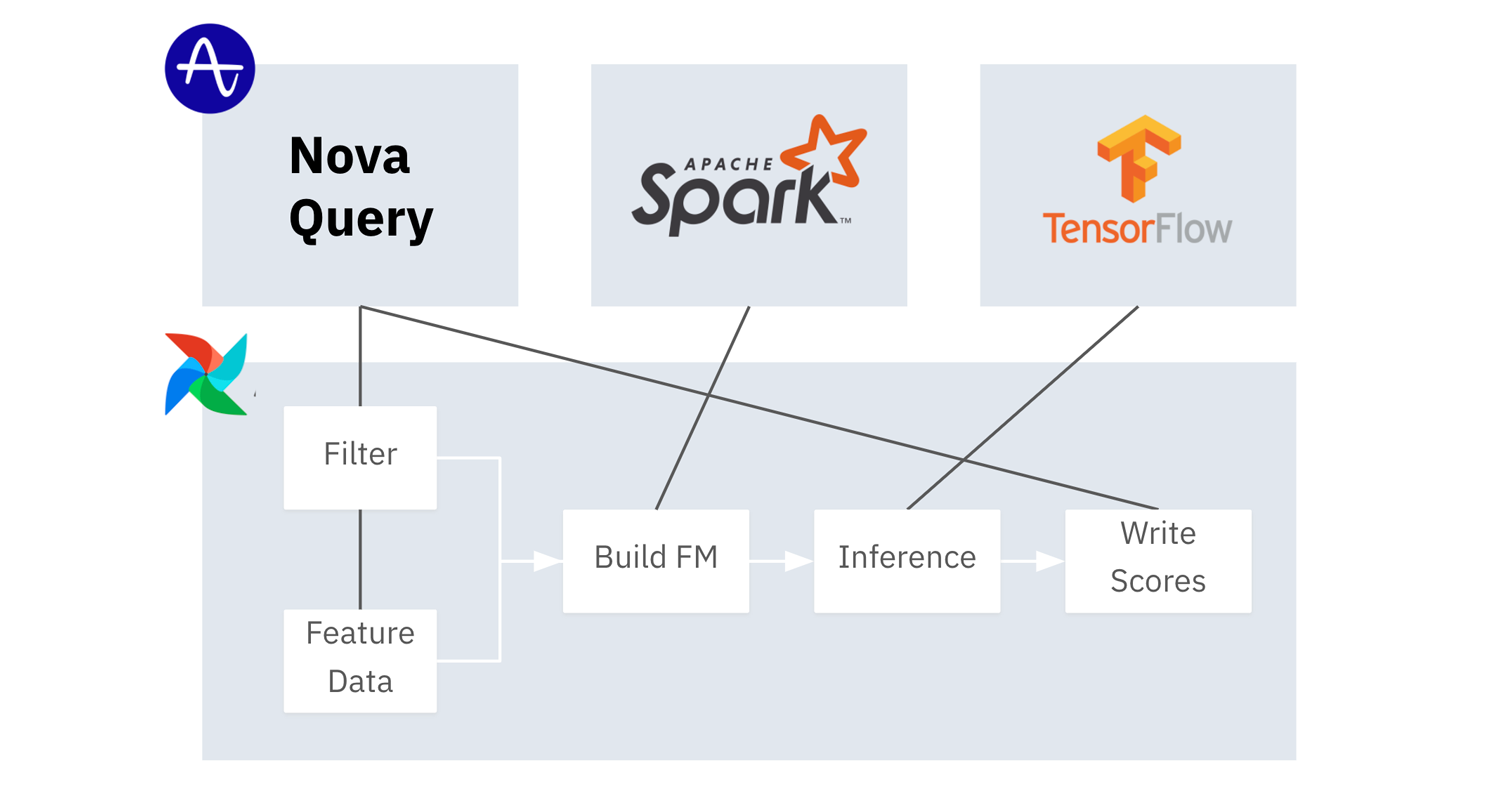
Upon model training completion, a separate Airflow inference pipeline is initiated for the prediction that was created. The inference pipeline generates a feature matrix on each inference run, based off of fresh user aggregates updated hourly. The pipeline uses SageMaker to load the feature matrix and the previously trained model from Amazon S3, and computes user scores per predictive outcome, to be written back into Nova Query at the user level.
This entire process, end-to-end, enables Nova AutoML to run most predictions in under 20 minutes, without any human intervention. Once initiated, the predictions refresh hourly so Nova Query persists the most up-to-date probabilistic values for all users in the respective predictive insights powered in Amplitude.
Next, we’ll dive deeper into the specifics of how we implemented each step of Nova AutoML—feature engineering, model training, predictive inference—to generalize to any dataset, for any customer, at any scale.
How We Automated Feature Engineering
Put simply, the data in a feature matrix is the data that a predictive model will learn from. As Amplitude is , this data is typically a set of user events and properties collected from websites and apps in our .
For instance, an event may be “click,” have an event property of “button” with value “checkout,” and a user property of “device type” with value “iPhone 6.” This data in its raw form is stored in JSON files and time-series format within Nova Query.
To construct a feature matrix consumable in model training, Nova AutoML needed to transform the data from an event-based format to a user-based feature aggregate. Each row in the matrix constitutes an individual user, while each column corresponds to a windowed aggregate of booleans/integers of a respective property/event.
Defining a Rolling Window
A rolling week window is calculated from the same time of day as when the prior week window ended.

For event-based feature aggregations, the majority of features correspond to rollups by some time period. For instance, one feature would correspond to the number of times a user performed “click” in the last seven days. To account for seasonal data, we compute eight rolling-week aggregates per event, computed on the hour.
For user properties, like “device type”: “iPhone 6,” we compute the first or last value recorded for an individual user in the time period. Because our models require data to be in numeric format, we the results. The computation outputs a boolean of 0 versus 1 for each user property-based feature.
Feature Processing
The feature engineering process first defines from the Taxonomy which data is applicable for feature engineering, queries aggregates on that data from Nova Query and then transforms those results where applicable via Spark for ML consumability.
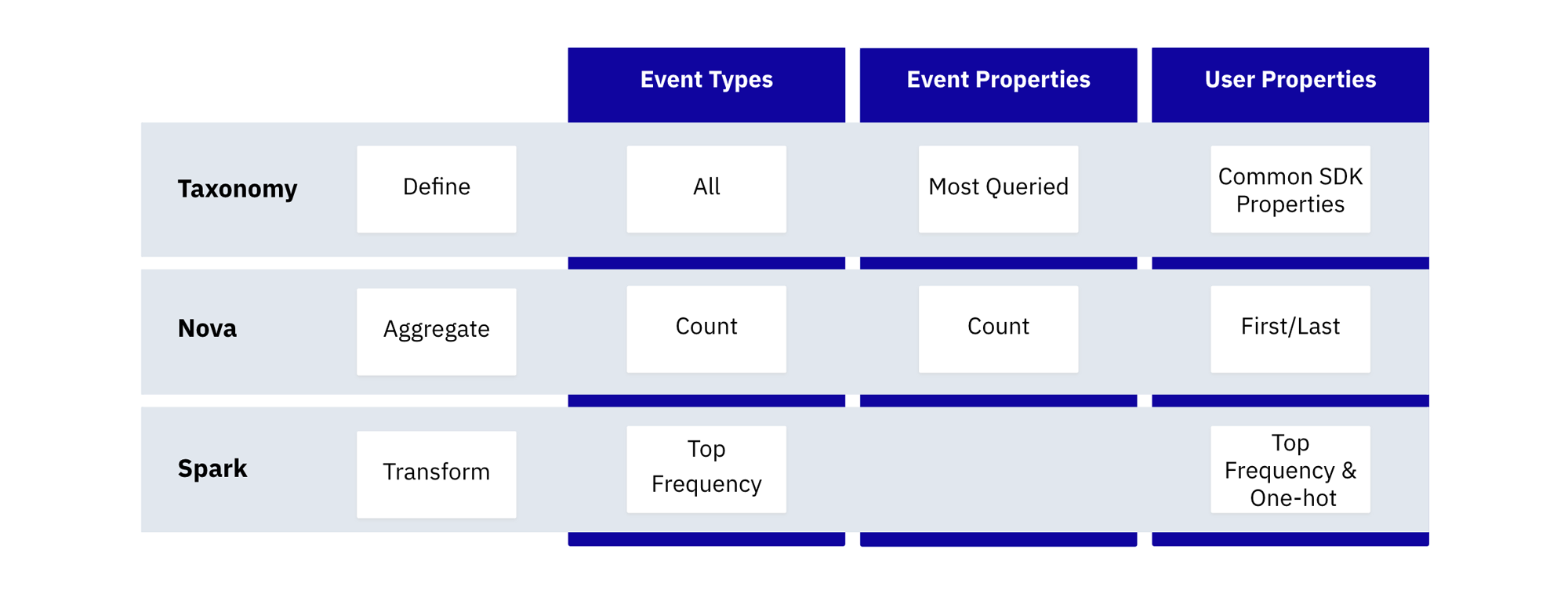
A challenge in generalizing the computation of features for model training is cardinality. High cardinality data can be expensive to represent in a feature matrix and can result in high model variance.
We limit the events aggregated to just the top-most logged in the customer’s dataset because lower frequency events are unlikely to provide much signal to the downstream model. For event properties, we compute aggregates for the most commonly queried event properties used by the customer in Amplitude, as a proxy for which event properties are most important to the customer.
Another challenge of generic feature engineering is (specifically covariate shift). To avoid it means ensuring that the feature matrix that is used in training has a similar distribution to the feature matrix that is used in inference.
One way this dataset shift can occur is when feature aggregates are computed on a more discrete basis than when training occurs. For instance, if feature aggregates were computed for hourly windows but feature engineering occurred once daily, there is no guarantee that a feature matrix generated on Monday at midnight for training would have a similar distribution as one generated for inference on Monday at noon. One case it would shift would be that users are less likely to open an email at 9:00 a.m. on a Sunday than at 9:00 a.m. on Monday.
To account for this specific cause of data shift, all feature aggregates in Nova AutoML are computed on a rolling basis windowed to a longer time frame than the frequency of training. So if Nova AutoML is forecasting an outcome over the next week, it will train the underlying model once a day.
Training Algorithms Without Humans
Training in Nova AutoML is built to leverage the results of feature engineering to predict the target label feature vector for any set of algorithms (logistic regression, random forest, etc.). The model trains on 80% of the data and validates the results on 20% of the input data to .
A common mistake in the construction of feature vectors for training is signal leakage. This can happen when the feature aggregation is calculated over the same time period as the label data. If you have an input feature variable of a Plan Type of “Enterprise” and the target label is “Upgrade to Enterprise,” the model is going to claim to be 100% predictive. To account for this, Nova AutoML uses Nova Query’s functionality to ensure all input feature vectors are offset by at least one time period prior to the target label occurrence.
A second pitfall of generalized model training is one of class imbalance. This occurs when the predictive label occurs extremely infrequently. For instance, if only 10 out of 100,000 users perform the “Upgrade to Enterprise” event every week, there is not likely to be enough signal for the model to build an accurate model, and training will simply be incentivized to label all users as unlikely to upgrade. To account for this, Nova AutoML rebalances training data, using an objective function that disproportionately rewards correct classification of examples of the minority class.
Unfortunately, by correcting for class imbalance, the model output loses its underlying probabilistic meaning. So we used isotonic regression—a technique—to allow for the output of our model to actually represent probabilities.
Lastly, all of these processes had to run at scale and in under an hour. Given the power of Nova Query’s underlying architecture, this remained true for most models during development. But as some of Amplitude’s customers have hundreds of millions of users processing billions of events every week, we instituted a user-level sampling on larger models. We found that models received diminishing returns on signal after a certain threshold of users—typically around 5 million users—and so we capped the sample size for training at that level.
Predicting Inference at Scale
A major challenge in building Nova AutoML was inferring at scale.
Using SageMaker’s infrastructure to power the inference components handled a lot of the parameterization and autoscaling necessary to run predictive models in parallel. The system runs two sets of inference jobs: model endpoints and batch transforms.
Model endpoints take the trained models from the previous step, and infer in real time user-level probabilistic scores given the input feature vector. Each user score needed to in turn be tied back to an internal ID. We had to implement a wrapper around SageMaker’s batch inference endpoint to accomplish this mapping.
To further reduce cost and compute efficiency, we run the batch transform every hour only on those users who were active in the last hour, and separately run it once a day for all users. As much of a customer’s user base may be inactive in a given hour, this enabled compute efficiency to scale Nova AutoML to work for customers of any size.
Using Nova AutoML for Product Intelligence
Nova AutoML effectively advances the Amplitude ecosystem to provide predictive insights at scale to our customers.
By automating the steps of a machine learning model—data transformation, model training, predictive inference, and model deployment—and ensuring they generalize for customers without human intervention, customers of Amplitude for the first time will have self-serve predictive insights coupled with a real-time analytics platform.
Nova AutoML is the technology powering these predictive insights. It will be leveraged for a variety of different product features we have planned over the coming year. Be sure to sign up for our virtual product conference, , to learn more about what’s to come.