Intelligent Data Governance with Amplitude AI
Data Assistant powered by Amplitude AI provides intelligent recommendations and automation to help make data governance effortless

One of the things we love to hear from our customers is how Amplitude has helped more people in their organization unlock insights about their products. Self-service analytics can remove bottlenecks and shorten the time it takes to get insights from weeks to real time.
However, the biggest learning we've had over years of working on this problem is that it doesn't matter how powerful or easy your analytics is if you don't trust your data. Everyone needs a shared understanding of the data you're collecting to ensure each team member has context for using that data. Effective data governance practices can help build that trust.
What makes data governance difficult?
Trusted data is critical for teams to unlock faster insights. We've learned from our customers that as they collect more product data and have more teams using Amplitude, it becomes harder and harder over time to keep everyone in sync on the meaning of their data.
With multiple teams contributing and consuming data in real time, how do you keep a shared understanding of everything you've collected and avoid data silos? To unlock insights and enable self-service for your organization, it takes a lot of painstaking work to maintain best practices and good data governance. We believe that Generative AI can play an important role here.
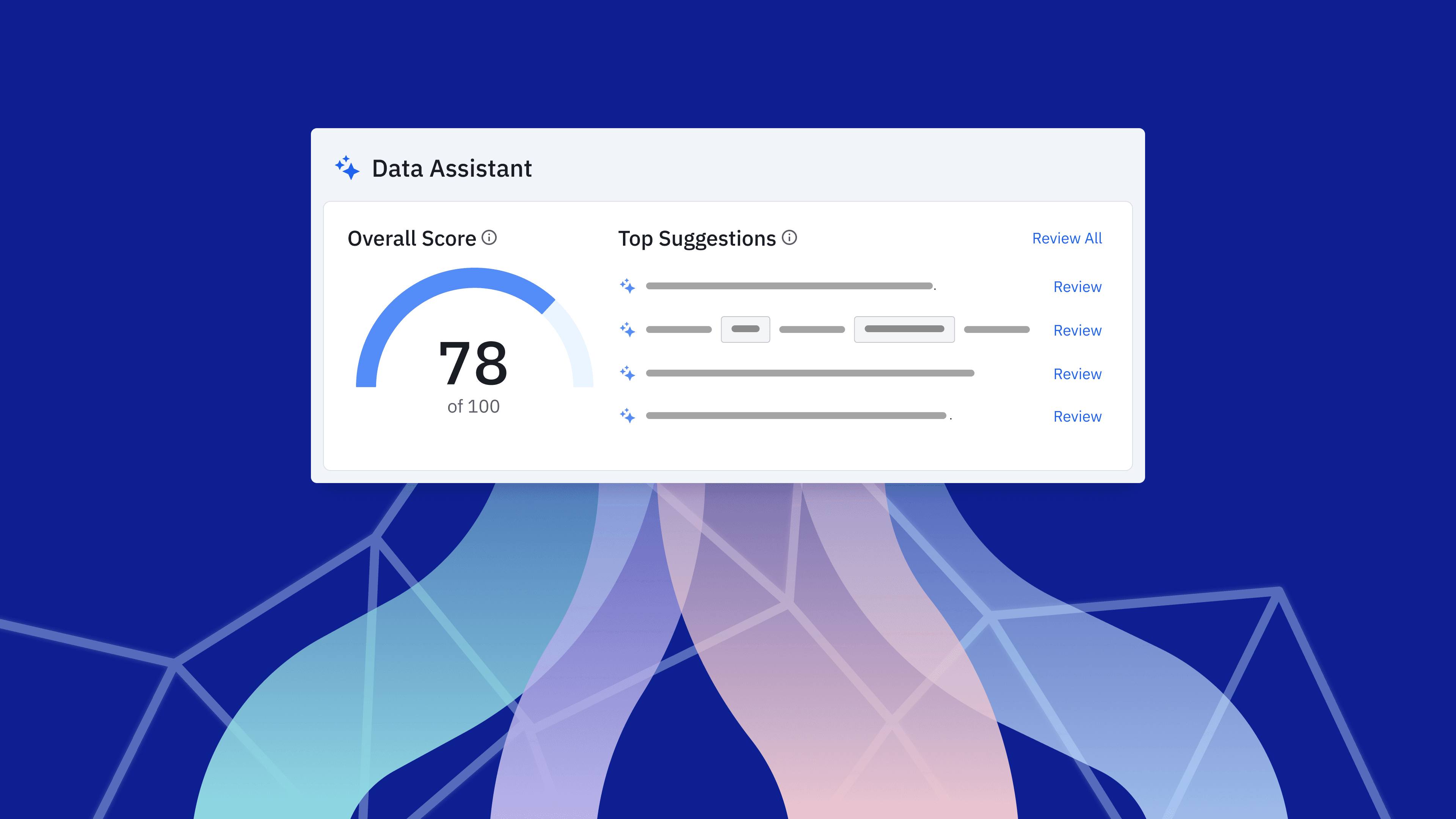
Introducing Data Assistant powered by AI
We’re excited to introduce a new way to supercharge your data governance. Our new Data Assistant feature, powered by Amplitude AI, provides intelligent recommendations and automation to make data governance effortless, and makes maintaining and improving data quality easier for everyone in your organization.
Let's dive into a few details about how we make this happen.
Consider the events you track using Amplitude today. Some of that data might be more important than others. For example, a purchase event on an ecommerce site is likely more critical to your business than viewing a product detail page. Our AI-powered Data Assistant looks at a combination of factors—including the number of queries on each data point and the event volume—to determine an importance score.
Next, Data Assistant also evaluates each event against best practices we've found working with thousands of companies. For example, grouping similar events into categories helps other Amplitude Analytics users find the event they're looking for more easily.
By combining event prioritization and categorization, Data Assistant can aggregate a list of suggestions companies can make to improve their data quality.
Having a recommended list of these suggestions is great, but imagine trying to execute this across a large taxonomy. Going event-by-event, adding a description, categorizing, setting an owner, etc. is not an efficient way to work.
To make this process easier, we've taken learnings from how our customers actually work and incorporated them into Data Assistant.
For example, instead of just identifying that several unrelated events are missing categories, Data Assistant finds similar events and suggests a category grouping appropriate to these events.
We use two methods for determining event similarity. The first method learns from the sequences of events in your own data to identify common patterns, while the second method uses semantic embeddings of the event names to identify common concepts. Both of these are combined to create the final recommendations.
Data Assistant also integrates the latest in AI technology, large language models (LLMs), to provide suggested text for your descriptions. Behind the scenes, we're leveraging OpenAI with description metadata—like the event name and category—to generate a description for you. We've built all of this with privacy and security in mind, following our AI principles.
And, as part of our commitment to transparency, description suggestions leverage OpenAI's APIs with controls in place so that no data will be used to train or improve OpenAI’s models and a strict 30-day deletion policy. When using Data Assistant, you can be confident that none of your end user data will be sent to OpenAI.
A single view of your data quality
All of this machine learning comes together as curated suggestions on your data homepage, where we use the event importance and suggestions to create a score for your taxonomy, along with a list of recommendations to make your data governance as efficient and seamless as possible. We order these suggestions so the ones at the top will have the most significant impact on your data usability (and your score). In many cases, you can simply choose to accept or reject the suggested values.
We're just getting started
Our Data Assistant is now available in open beta to all customers, and we're just getting started. We've focused on helping you improve the usability of your data, creating a consistent, shared understanding of your taxonomy across your organization. Over the coming months, we'll be adding even more suggestion types, including insights into the health of your data.
Try Data Assistant today, and as always, we're eager to hear your feedback.

Alan Okada
Principal Product Manager, Amplitude
Alan Okada is a principal product manager at Amplitude. Previously, he was a senior product manager at Rosetta Stone and senior product owner at Napster.
More from Alan


