A Guide to Implementing a Successful Data Governance Framework
Clean, high-quality data doesn’t happen by accident. You need a system that builds a culture of data integrity.


This blog post was co-authored by Jessica Chiu, Professional Services Manager, Amplitude, and updated on November, 16, 2022.
Clean, high-quality data doesn’t happen by accident. You need a system that builds a culture of data integrity.
When any company begins their data journey, they often have a small number of data sources and people managing their data assets, so it’s easy to keep their data taxonomy clean.
But as those companies scale their programs and begin to draw key insights, the complexity of their data and the number of inputs involved also increases. If they struggle to manage this information, they may face several costs.
“Reliable and relevant analytics are important from the get-go, and they are not achievable without some data governance,” says Avo CEO and Co-founder Stefanía Ólafsdóttir. “Scaling product and go-to-market efforts make data reliability and product delivery speed more important, while a growing team makes data reliability more difficult to manage. In other words, the more you need data governance, the more difficult it becomes.”
According to Gartner research, “organizations believe poor data quality to be responsible for an average of $15 million per year in losses.” And with growing regulations around data privacy, such as the GDPR and the CCPA, companies have to be careful about what data they track and be able to access and remove specific data as required.
Instituting a data governance framework increases the integrity of your data because everyone is working from the same taxonomy and standards. With this framework, you minimize data misunderstandings by creating clear and effective data practices.
What is a data governance framework?
A data governance framework is a system that your team can use to establish overall data standards and processes. That includes resources and trainings that capture the planning, education, and maintenance standards of your data. An effective process does not need to be heavy-handed but rather intentional and structured.
Our best-in-class customers have taught us that there are three key pillars to these programs:
- Education: Defining and executing the process of documenting, educating, and sharing your data standards with your team.
- Instrumentation: What your data standards are and how to use them to instrument your data.
- Maintenance: Who is in charge of ongoing data usage questions, management, and updating standards.
Following these pillars is key for organizations that want to use product analytics. Tracking user behavioral data isn’t meaningful unless you’re assessing high-quality data.
Why you need a data governance framework
It is easy for data to depreciate in value if there is no framework to dictate how you should add, manage, and maintain data.
Consider the following scenario: Company A does not have a data governance framework. Product team X labels their events with underscores between words, Product team Y uses hyphens for their labels and Product team Z doesn’t follow any conventions at all—with some events even labeled “test.” Someone then creates an executive dashboard to report on key company metrics and cross-product KPIs, but the report only pulls events with hyphens, which means the data is incomplete.
Incomplete data can, at best, lead to embarrassing data misinterpretations. For example, a graph on a report shows that the majority of customer acquisition happens through email, but the marketing team can easily show that’s the case for only a subset of products.
At worst, incomplete or misleading data can drive decisions that hurt your bottom line, such as shuttering valuable features or inadvertently failing to comply with government regulations.
3 pillars of a data governance framework
Build a culture around keeping data assets organized by establishing a plan for educating your team, instrumenting a taxonomy, and identifying roles for maintenance.
Pillar 1: Education
Create an education plan to outline how your teams learn about your data governance standards and how they can access those standards.
Your education plan should address the following:
- How to gain access to your data tools
- Quick start guides for data literacy, taxonomy design, and instrumentation
- How a member of your team can read the data, for instance:
- What are key events as well as official charts and dashboards
- What are some generalized events that are common across the organization
- How the data is governed, including how it’s managed and maintained
- What is the team’s ongoing maintenance plan as well as escalation process when changes are needed
- What is the instrumentation workflow, including templates or examples of how this process is managed
At Amplitude, we recommend including information about your data governance during new-hire onboarding. Highlighting the process for planning, instrumenting, and reading an initial set of events shows team members that data integrity is a priority from the beginning.
Because data evolves as your systems and processes change, it’s good to maintain a data taxonomy within a single source of truth. This resource helps your team understand and read the data easily. Include a data dictionary in your education plan and a guide for adding to the dictionary.
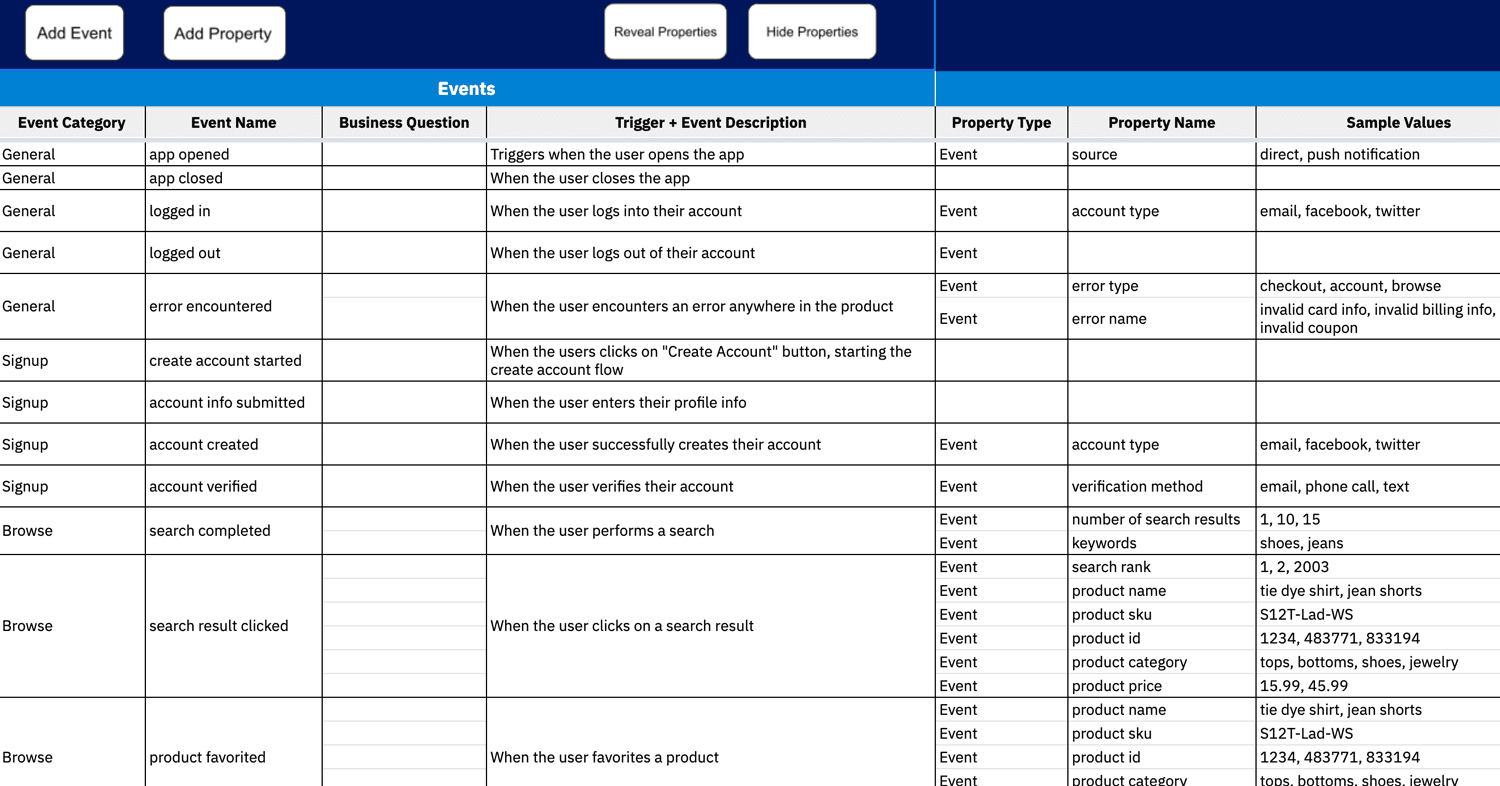
Sample event taxonomy for an ecommerce product
House your education plan and data dictionary in a shared location within Amplitude or an internal document repository so both trainers and trainees have access. Or use a tracking plan tool such as Amplitude’s Data Governance to host all your data governance documentation and create a single source of truth for all data stakeholders.
Pillar 2: Instrumentation
A comprehensive instrumentation workflow and taxonomy style guide sets the foundation for clean, easy-to-understand data assets.
When building your taxonomy guide, be sure to address the following:
- What is the taxonomy for your data, such as the syntax and nomenclature
- What are some generalized event standards and properties that should commonly be used
- Who designs and approves the taxonomy
- How the data is constructed and applied
Remember to collaborate with your engineering and design teams to identify the product metrics that answer questions such as, “What does success look like?” and “What does failure look like?” These metrics should be spelled out in your taxonomy guide using the templated syntax to address additional data needs.
The next step in the instrumentation pillar is to identify who will design the taxonomy—a data team, a lead product manager, an engineer, a designer, or someone else. At Amplitude, we’ve found the centralized data governors or product managers are most likely to design the taxonomy because they are the person most likely to be familiar with your data.
With your key metrics established and the person designing the taxonomy identified, it’s time to build your taxonomy style guide. The primary goal of any taxonomy is that it is functional. Make sure the nomenclature is consistent, human-readable, and descriptive. Considering how your team refers to different features and customer behaviors is helpful.
Include elements such as:
- Casing (all lowercase, for example)
- Syntax (verb plus noun, with spaces)
- Verb tense (present versus past tense)
These elements should be consistent across events and properties. For more details on the different elements, check out our help documents.
Example event taxonomy style guide
All taxonomies should evolve and grow as your company’s goals, focus, and products will change. You should regularly revisit your taxonomy as your company and key metrics adapt to your new phase of business.
Once you have a taxonomy guide drafted, share it with the engineering team, and expect to make some compromises based on technical constraints. When your taxonomy is ready, make the documentation or tracking plan available in Amplitude Data, a shared Google Doc, Confluence, or GitHub repo so anyone can access it during development.
Learn more about designing your data taxonomy in our Fundamentals of Data Taxonomy Design course. Then, get started with instrumenting your data using our Guide to Behavioral Data & Event Tracking.
Pillar 3: Maintenance
The final piece of the data governance framework is to clearly outline who to contact for questions and updates to the framework, as well as how the documents in the framework will be distributed.
When documenting the maintenance pillar of your framework, be sure to address the following:
- Who the data governors are
- How your team reports data issues
- How your team resolves data issues
- How often your team will review the existing taxonomy and address any changes that are needed
Your data governors are the people most able to address questions related to specific aspects of your data governance framework, such as general data issues or suggested updates to the taxonomy design.
This can be a single point of contact (e.g., a product manager who helped craft the original foundational taxonomy) or a data governance team consisting of cross-functional members.
In terms of reporting data issues, determine whether team members should contact the appropriate data governor directly or whether there is a specific channel team members should use.
The final piece of the data governance framework is to outline how the pieces of the framework will be distributed.
Are they all located in the same location in Amplitude, Google Drive, or Confluence? Will different teams include them in their own documentation repositories? Or is everything in a data governance tool? Understanding where this information will live will make it easier to update them when there are changes.
High-quality data requires a solid framework
There is no magic wand for clean, useful data, but establishing a clear data governance framework will help. With these guidelines, your team will have the information they need to maintain high-quality, standardized data assets.
Looking for help with your data governance practices? Reach out to a product analytics expert to see how Amplitude helps customers streamline their taxonomies during the onboarding process.
Resources
- Data Taxonomy Playbook
- Fundamentals of Data Taxonomy Design Course
- The Amplitude Guide to Behavioral Data & Event Tracking


Ganit Bar-Dor
Sr. Director, Global Professional Services, Amplitude
Ganit Bar-Dor manages Technical Services & Success at Amplitude, working with companies to gain actionable insights and effectively manage their data. She has worn many hats within professional services and product teams, building, executing and consulting with customers. Ganit Bar-Dor graduated from Concordia University in Montreal, Canada, with a degree in Computer Science.
More from Ganit


