A Pledge to Increase Fairness in Amplitude’s Machine Learning Systems
Ensuring fairness in machine learning is important but not straightforward. At Amplitude, we are investing in solutions to address different conceptions of fairness, such as equalized odds, equalized opportunities, and demographic parity.

*Contributing authors: Jenny Chang, Bilal Mahmood, Cindy Rogers *
Machine learning is a tool. A powerful tool, but built by humans, and therefore a product of the biases, data, and context we use it in.
This tool can result in significant ethical challenges and injustices such as criminal prediction systems that say Black defendants pose a higher risk for recidivism or predictive ad systems that show high income jobs to men over women.
This problem extends to product analytics as well. Thousands of teams use data to make product decisions that affect billions of users across the globe. They forecast outcomes like who will purchase or what content they will view, and as a result they have the power to personalize pricing and content to every single user. By not paying attention to this now, companies could release personalized experiences unintentionally biased against protected groups — like pricing discounts skewed to one race or application recommendations skewed by gender.
We have an ethical duty to ensure these personalized experiences have minimal inherent bias. So today at Amplitude, we are pledging to invest in improving the fairness of the machine learning infrastructure that powers Amplitude’s product intelligence platform.
We are cognizant there is no silver bullet here. This will be an ongoing and difficult effort. But we wanted to make our pledge public so that our customers know the predictive insights they derive in Amplitude will have a higher guarantee of fairness. In turn, we hope that both our customers and the ML community gain insight into how to approach this problem in the context of analytics.
What Is Fairness?
What is meant by a “fair” machine learning model?
Before describing the solutions to fairness we will be investing in, it’s important to diagnose how the problems occur. Below we outline two categories of interest to analytics that Amplitude will be investing in: Predictive Fairness and Social Fairness.
Predictive Fairness
Predictive fairness means that a statistical analysis performs similarly across different groups in a protected attribute (e.g. race, gender, age, etc). The measures for performance can vary, but in the context of analytics, we’ve focused on two: equality of odds and equality of opportunity.
Equality of odds is when a predictive analysis has an equal rate of true positives (sensitivity) and true negatives (specificity) for each group in a protected attribute. Descriptively, sensitivity measures the proportion of actual positive data points that are predicted positive, and specificity measures the proportion of actual negative data points that are predicted negative.
Colloquially, this means equality of odds is satisfied if we are correctly predicting both outcomes — the positive cases and the negative cases — at equivalent rates across the protected class.
Take a common use case in ecommerce: predicting lifetime value (LTV). Let’s assume there are only two values for LTV — high and low. If the proportion of high spenders correctly predicted with high LTV, or the proportion of low spenders correctly predicted with low LTV, is greater for one gender over another, equality of odds is not satisfied. Uncorrected this can lead to downstream pricing discrimination. For example, offering discounts proportional to a user’s predicted LTV, when equality of odds is not satisfied, can result in users of two different genders receiving different discounts even if their rate of spending was the same.
Equality of opportunity is a more relaxed measure for predictive fairness. It is when a predictive analysis has an equal false negative rate for each group in a protected attribute. False negatives, for context, are the proportion of actual positive data points that are predicted negative.
Colloquially, this means equality of opportunity can be satisfied if we are correctly predicting just the positive cases, at equivalent rates across the protected class.
Back to our ecommerce example: If the proportion of high spenders incorrectly predicted as having low LTV is greater for one gender over another, equality of opportunity is not satisfied. But the opposite case — unequal prediction rates of low spending users — would not violate equality of opportunity as it only cares about the positive class.
The question of which measure to use — equality of opportunity where only the positive cases matter versus equality of odds where both positive and negative cases matter — will depend on the application. In the above example, if both high and low spending users may receive discounts, equality of odds is more prudent. But if only high spending users may receive discounts, only the positive cases matter, and equality of opportunity may be sufficient.
Social Fairness
If predictive fairness is focusing on the algorithm of an analysis, social fairness is about the underlying data. Even if an algorithm is predictively fair, it may give results that perpetuate a system of inequality that exists in our society, and are represented in the historical data we use to train a predictive algorithm or analysis.
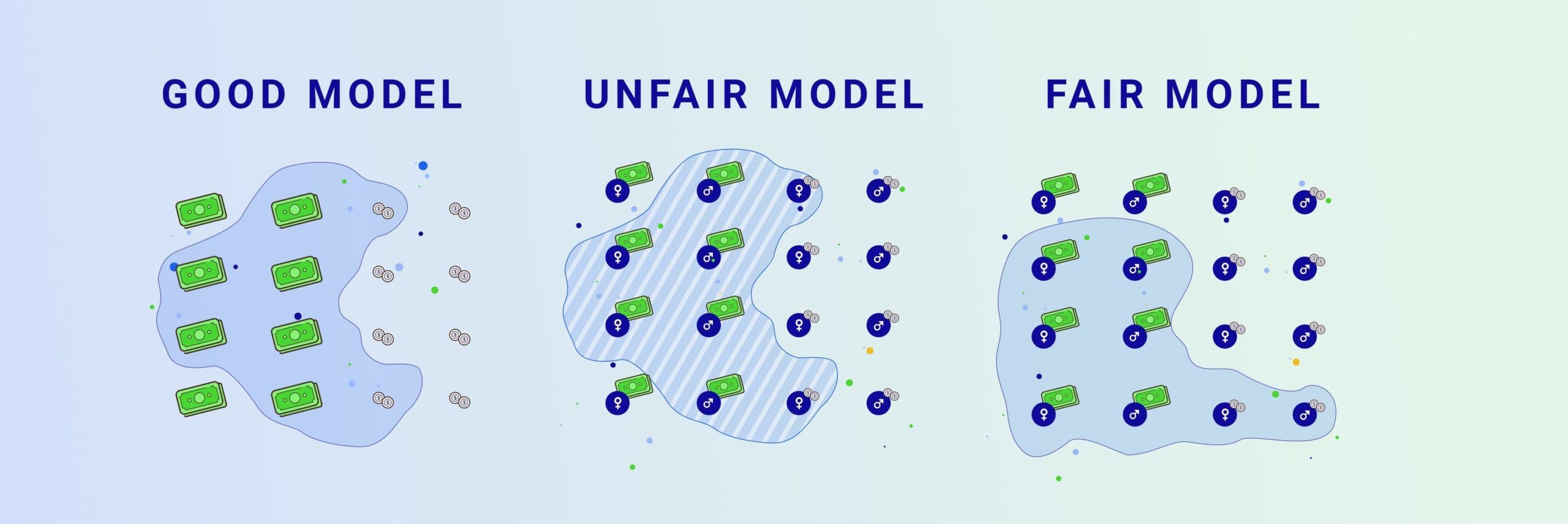
One of the common measurements for social fairness is demographic parity. This means that every group in the protected attribute has an equal probability of getting a positive outcome from the prediction. Colloquially, this means demographic parity is satisfied if the rate of the positive outcome is representative of the demographic proportions of the population.
For example, if 18% of high spenders were people of one gender, then demographic parity would be satisfied if 18% of users predicted with high LTV were people of that gender. In turn, this would ensure that downstream the percentage of discounts offered to each gender is proportional to their representation in the population.
Note, ensuring demographic parity does not necessarily ensure predictive fairness, and vice versa. Take for instance this study on predicting college admission rates based on historical graduation rates. As the underlying data itself indicated that graduation rates were higher for white students than Black students, a predictively fair algorithm would give white prospects a higher predicted score for admission than Black students.
This seems unfair of course. Because the social context and historical system of oppression cannot be easily represented as data inputs, a predictively fair algorithm that satisfies equalized odds and opportunity can still lack social fairness.
Improving Fairness
So how do you ensure predictive fairness and social fairness in analytics?
The solutions to these problems can be tricky, given the tradeoffs between ensuring equality versus parity. Below we cover a couple approaches in broad detail — feature blinding, objective function modification, adversarial classification, and thresholding. In future posts, we plan to detail the exact methodologies we leverage at Amplitude.
Feature Blinding
The simplest approach to removing bias against certain demographics is to simply remove the protected attribute (e.g. race, gender, etc) as an input into a predictive analysis. Consequently, those attributes would no longer directly bias the model in a specific direction.
This seems good in theory, but is often insufficient. Even if we remove the protected attribute, other attributes that correlate with it may remain. For instance, browser or device type may be strongly correlated with race. And as a result, the predictive model we build could still learn racial bias through the indirect relationship between device type and race. We could attempt to remove these correlated attributes, but we’d likely lose too much important signal for our model to be of any utility. Also ironically, by blinding a model to the protected attributes, it makes us unable to correct for their relationship with the correlated attributes.
The statement “I don’t see race” is just as problematic in data as it is in social contexts.
Objective Function Modification
Much research has been done into solutions that can satisfy predictive fairness without blinding the algorithm. One such optimization is to change the objective function towards which our predictive model is being optimized.
Most predictive analyses are optimized around maximizing an objective function tuned for accuracy of the outcome. To reduce bias, we can add different metrics to the objective function. Instead of just accuracy, we may have our analysis optimize for equality of odds and/or opportunity by simultaneously optimizing for desired values of metrics, such as overall parity between demographic groups, or independence from demographic variables.
The observed accuracy of the analysis may decline slightly, but the effect is often not too significant. Indeed, this analysis may sometimes compensate for spurious correlations, like race to device type, as well.
Adversarial Classification
A technique that can address concerns of accuracy while respecting protected attributes is adversarial classification. In this case, we create simultaneous predictive models — one optimizes for a correct prediction of our desired outcome, and the other optimizes for a poor prediction of our protected attribute — essentially, no better than randomly guessing it.
Let’s take the example of predicting LTV. A model optimized via adversarial selection would optimize for maximizing the accuracy of predicting LTV of a user, but be optimized for minimizing the accuracy of predicting the race of that user.
The result could be an analysis that produces more equitable outcomes for users without unduly sacrificing quality.
Post Processing Optimization
A technique to correct more exclusively for demographic parity is post-processing optimization.
This involves modifying the output of a predictive analysis after it has been completed, ensuring that the predicted positive case is equally representative of the protected group in question. For instance in our predicted LTV example, say we want to send discounts to the top 10% out of 1000 users. However, even though Black users represent 200 of the 1000 users, there are no Black users predicted in the top 10%, and as a result will not receive a discount. We can correct for this by changing our post-processing selection criteria to choose the top 10% of each protected class. This ensures that at least 20 Black users will comprise our discount selection criteria for top 10%.
This post processing optimization can accordingly correct for the socio-economic differences system to our dataset, and ensure more demographic parity in the outcomes of our system.
Conclusions
The issue of ensuring fairness in machine learning, even in the context of analytics, is an important but by no means straightforward one.
We have to balance the tradeoffs of optimizing for predictive fairness with social fairness. We have to identify whether techniques of feature blinding, objective function modification, adversarial selection, or thresholding are the best tool for maximizing the desired fairness criteria along protected classes. And even then, as protected classes aren’t binary (e.g. there aren’t just two races), the complexity of permutations can make it difficult to find just one criteria.
At Amplitude, we are pledging to invest in solutions that can ideally address different degrees of equalized odds, equalized opportunities, and demographic parity. As an analytics platform, we’re fortunate to be uniquely positioned to bring greater transparency to the issue — either through direct bias reduction in the predictive models our customers leverage in Amplitude, or a fairness score by protected attribute, displayed for any predictive insight generated.
We look forward to documenting and sharing our concrete implementations to these solutions in the months ahead.
Resources
Videos:
- The Trouble with Bias – NIPS 2017 Keynote – Kate Crawford
- Inclusive AI – F8 Keynote 2019 – Lade Obamehinti
Articles:
- How to define and detect discriminatory outcomes in Machine Learning
- Equality of Opportunity in Machine Learning
- Adverse Impact Analysis / Four-Fifths Rule
- Machine Bias Risk Assessments in Criminal Sentencing- Propublica
Scholarly Papers:

William Pentney
Former Staff Software Engineer, Amplitude
William Pentney is a former staff software engineer at Amplitude. He focuses on providing insightful, efficient, and inclusive machine learning solutions for business analytics.
More from William


