

Amplitude has grown significantly both as a product and in data volume since our on the architecture, and we’ve had to rethink quite a few things since then (a good problem to have!). About six months ago, we realized that old Wave architecture was not going to be effective long-term, and started planning for the next iteration.
As we continued to push the boundary of , we gained more understanding of what we needed from a data storage and query perspective in order to continue advancing the product. We had two main goals for the new system: (1) the ability to perform complex behavioral analyses (e.g. and ), and (2) cost-effective scalability. After extensive research, we decided to build an in-house column store that is designed specifically for behavioral analytics. We call the resulting system Nova, and we’re excited to share the thought process around how we got here and some of the key design decisions we made.
Limitations of pre-aggregation
[Tweet “Nova: The Architecture for Understanding User Behavior”] One of the core principles of our existing architecture was the concept of pre-aggregation. Pre-aggregation is based on breaking high-dimensional queries down into simple, low-dimensional components, and then aggregating the components prior to the query. Then when the query is actually run, significantly less computation needs to be done, which makes pre-aggregated queries very fast. This is effective for a lot of different queries in behavioral analytics, ranging from to simpler forms of . The trade-off, of course, is that you have limited flexibility in the types of queries that can be run efficiently. If a query cannot leverage pre-aggregated results, then it is forced to do a full computation that is very expensive. Some of our new features like Compass and Pathfinder are significantly more complex than previous ones and cannot take full advantage of pre-aggregation. The upside of pre-aggregation is cost and speed, but the breadth of queries led to a fragmented and cost-inefficient system that was slow for the more complex queries. It became clear that we needed an overhaul of the query architecture that puts flexibility as one of the top priorities, thus enabling features that give our customers a deeper understanding of . For anyone working on analytics databases today, the natural choice is a (column store).
Overview of column stores
The idea of storing data in a column-oriented format in databases has been around for a long time (30+ years). provides a great summary of the history of column stores and the techniques that make them so effective. In contrast to a traditional relational database, which is optimized for reading, updating, and inserting single records, a column store is optimized for answering queries that scan a large dataset, which is the exact use case of analytics. In a column store, the data is structured in a way that allows for high performance despite the fact that queries have to scan considerable amounts of data to produce results. The main advantage of a column store over any sort of pre-aggregated system is that it offers great flexibility for queries, since all of the raw data is available. There are quite a number of column store technologies out there today (many of which happen have blue logos), and it’s useful to understand the differences between them. They can be broadly placed into one of three categories: services, commercial, and open-source. In the services bucket, we find the offerings of two of the big infrastructure players, namely and . These are by far the simplest solutions to get running, as they handle the management of the underlying machines for you. Both have SQL-like interfaces and can be used by anyone who has SQL experience. We are here at Amplitude, since it allows our customers to build reports using SQL. The main commercial offering is , which is the evolution of one of the first column stores, . It is one of the older products out there, and has a strong enterprise foothold in the space. Lastly, there are a couple of recent open-source column stores that we looked into. The first is , which is an extension that turns into a distributed database that can store data in a columnar format. This is cool because PostgreSQL is a widely-used and mature database (we run a few instances of it ourselves) that has many integrations already. , on the other hand, is an analytics data store built from the ground up for high performance and has its own query API that supports many different types of aggregations. For the vast majority of use cases, choosing one of these is the right decision, as they have done all the hard work already of building a highly-scalable system for analytical queries.

Advantages of an in-house column store
Given all of the existing work that has been done around analytical column stores, you would need compelling reasons to build a new one. We spent quite a bit of time understanding the intricacies of our use case and their implications on our technology; the end result was a handful of key advantages to an in-house column store:
- Query flexibility is one of the most important aspects of our database system (it’s one of the motivating factors for the architecture revamp in the first place!). We’re constantly innovating on the analytics we provide, so it’s important that we can handle everything from simple aggregations to machine learning algorithms.
- Our event data is immutable, and we can use that assumption to improve performance. There are a few special instances of mutability that we’ll go into later, but not having to support generic updates removes a lot of the complexity.
- An area where we have some leeway is . When we ingest events, it’s not essential that the data be made immediately available after accepting the write, only that it is queryable after a short period of time (typically a minute or so). In the same vein as immutability, dropping strong consistency allows for optimizations.
- Finally, we have more control over where and how the data is stored, which reduces costs. While all column-oriented databases are designed to be horizontally scalable, it’s necessary for us to operate cost-efficiently at high volumes since sampling is bad.
Furthermore, we have worked a lot with Amazon Redshift and have also explored Google BigQuery in the past. Ultimately, we always found use cases that were not supported, especially given the unique behavioral analyses we do, so having control over the underlying system has a certain appeal. There are significant downsides as well that we weighed against the advantages, namely the engineering effort required as well as the fact that we might have to reinvent a lot of the basic reliability and scaling mechanisms. Fortunately, we have some experience mitigating the latter by leveraging the , so it mostly came down to whether the time and resources spent developing our own system would pay off. Given that analytics and distributed systems are our core competencies, developing a competitive advantage in this space is a worthwhile investment. Thus we embarked on a multi-month journey to build Nova, an in-house column store that would scale with the company.
User-centric computational model in Nova
We think of Nova as a distributed columnar storage engine with a real-time computational model centered around the concept of users. We’ll first describe the model before getting into the details of how data is stored. As a reminder, one of our main goals was query flexibility, and MapReduce is a great fit as a generic framework for expressing many types of computations. One of the fundamental principles that we follow is moving code to data rather than the other way around. is highly dependent on looking at all the events for a user at once. In a distributed system, this amounts to performing a distributed join on user, which means that data needs to be partitioned by user to avoid moving it, hence the user-centric model. Once you’ve done this, a query can be highly parallelized by running independent workers on disjoint subsets of users. In our computational model, the reduce step assumes that it has the full view of a user’s events. For example, suppose you are computing the in an e-commerce application with steps Register => View Item => Add Item => Purchase. Given all of the events that a user has performed, it’s easy to determine how far they made it in the funnel. Now, assume that you compute the funnel conversion independently for users in disjoint sets A, B, and C that make up the complete user base. The important property of behavioral queries that we leverage is that the results of the query on subsets of users are small (not dependent on the number of users) and can be aggregated together. In this case, we see that the total funnel conversion is simply obtained by summing the conversion at each step across A, B, and C.
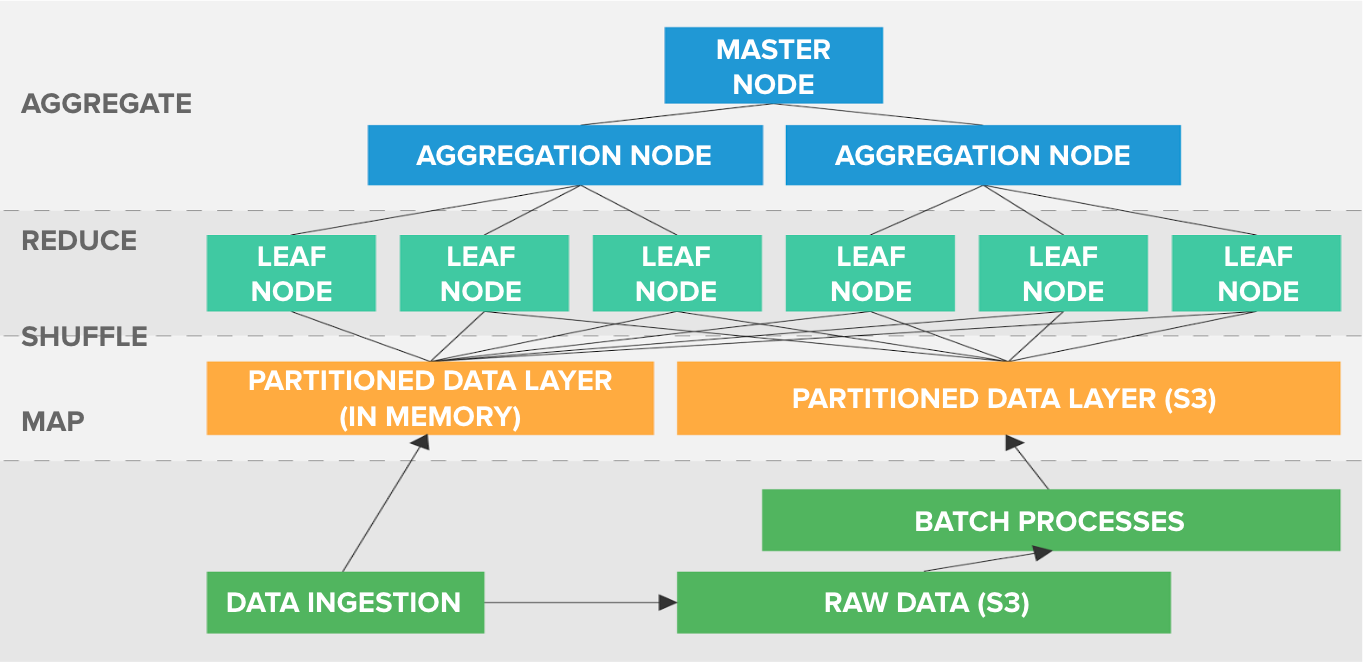
If you’re following closely, you may have noticed that, if the data is partitioned by user, can’t the shuffle step be omitted, thus collapsing map and reduce? There is one major caveat to this, which is the problem of . It is possible that, at any point in the future, we may gain information that two users within Amplitude are actually the same. We choose not to retroactively modify the event data since that violates immutability, so we instead apply a query-time mapping that tells us the true user for each event. This means that at the data layer, we do not have a fully-partitioned dataset, necessitating the shuffle; fortunately, since merging and aliasing only account for a small percentage of users, we incur minimal cost for the . Finally, after the reduce computes the query result on subsets of users, there is an aggregation layer that follows. While these results are small relative to the event data, they can still be nontrivial in size (e.g. when doing a large cardinality grouping), so we use hierarchical aggregation to eventually produce a single result to return to the client. MapReduce is a popular model of computation because it is both simple and flexible; nearly any type of analytical query can be represented as a MapReduce. In combination with the user-centric focus, we are able to efficiently analyze behavior across huge user bases. To reiterate the first advantage of an in-house column store, we are able to express behavioral queries such as Compass and Pathfinder within this model (albeit through writing code) that are impractical to do in SQL.
The underlying storage engine
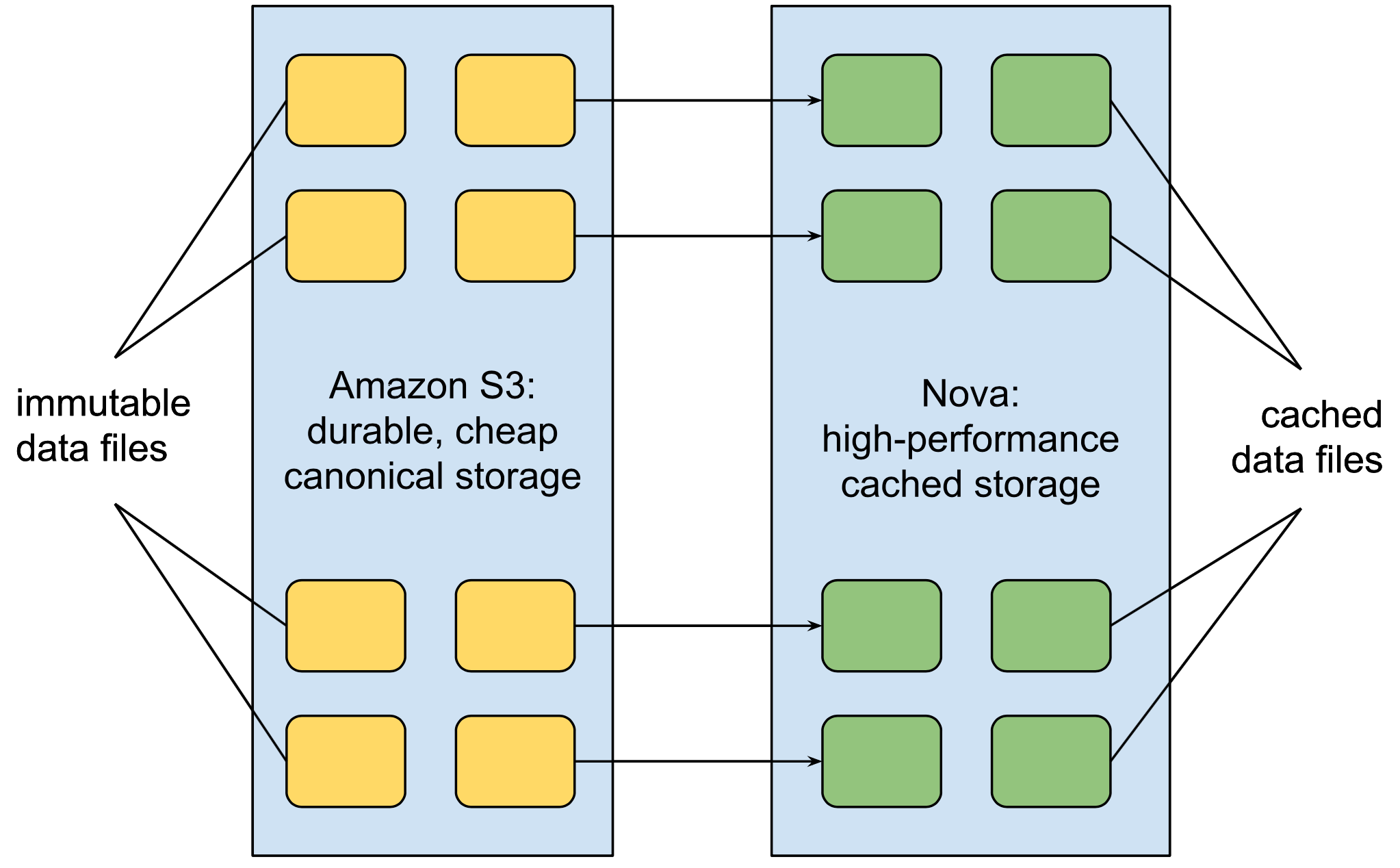
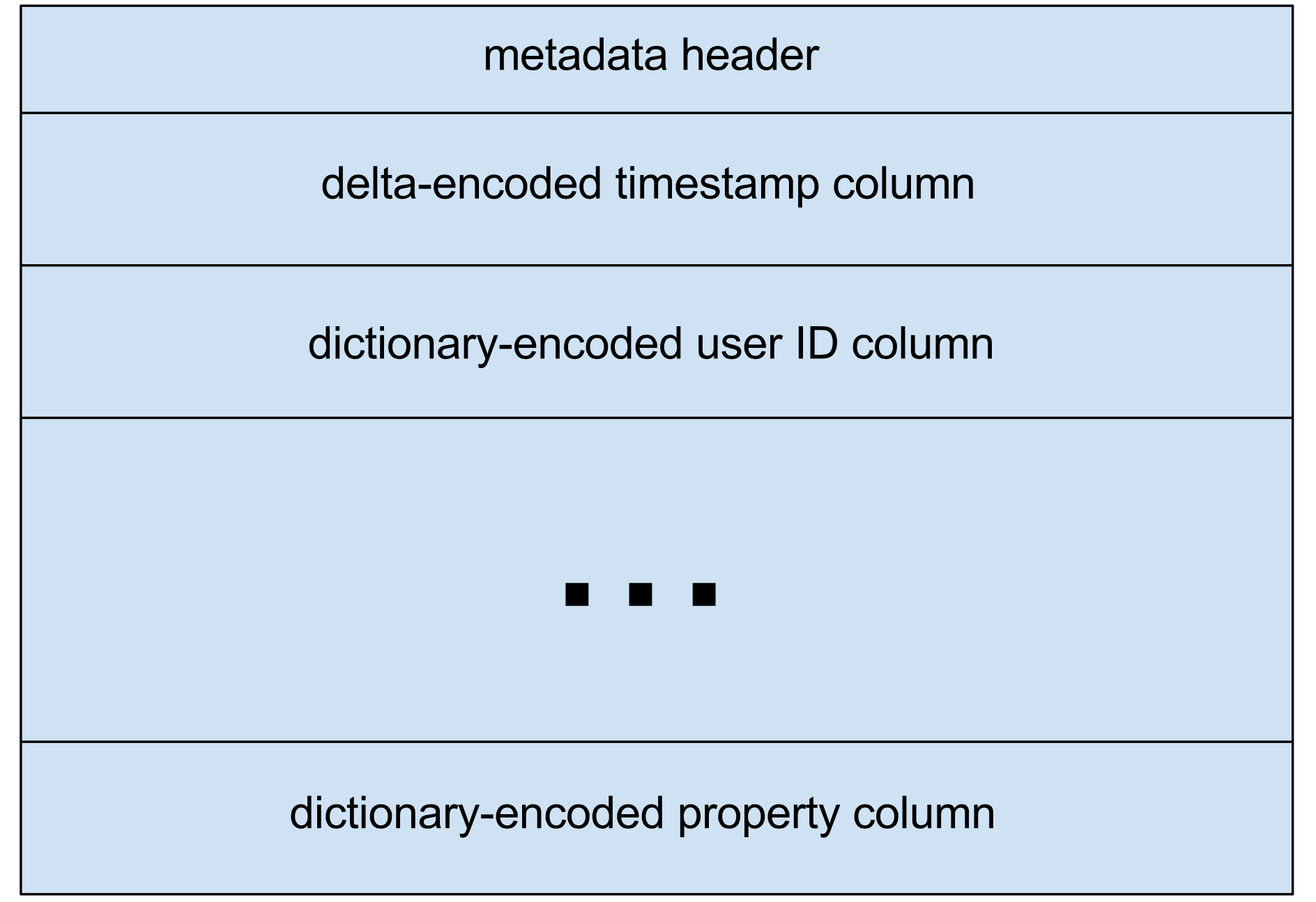
While there are a lot of changes from our existing system, one aspect that we decided to keep is the use of . To recap, lambda architecture is a design pattern that separates real-time ingestion from batch-computed data in order to localize the complexity and cost of real-time updates. Instead of these layers producing pre-aggregated results, they now convert the raw data into an optimized columnar format, but the benefits are the same. One helpful abstraction is separating the source of the data (real-time vs batch layer) from the query logic, so that all queries look like they operate on a single data format. Another similarity to our previous architecture is the heavy usage of AWS services, especially . We’ve written about the advantages of S3 in the past, but they’re worth mentioning again because of how much they simplify building systems. The key features of S3 that make it invaluable are its ) and cost; by using S3 as the canonical data store, we ensure that data is never lost even if we don’t implement any durability mechanisms ourself. Once you have that guarantee, everything else in the system can act as a cache on top of S3 and doesn’t have to worry about replication. We heavily leverage this insight to build services that are simple and stateless yet have high durability guarantees (and reasonable costs!). Given all of this, the final piece is what the storage layer of Nova actually looks like and the optimizations we have made to get the best performance. Data is broken out by users, time, and ingestion batch in order to have immutable chunks that can be managed easily; every day we produce a new set of chunks that are saved to S3. Given that the system functions as a cache on top of S3, you would typically expect to run into , but here immutability saves us. Since the chunks can never change, they do not get invalidated, and we only need to observe when new data is available. Once again, the caveat to this is information about merged users, but we built a separate mechanism for that as the scale is significantly smaller (the size of the merged user information is less than 1% of the raw data). Within a single immutable chunk of data, we apply many of the standard columnar optimization techniques to get high throughput on queries. This includes column-specific encoding and compression, such as timestamps and just about everything else, from User IDs to device types. Dictionary encoding turns out to be one of the most powerful forms of compression not only from a storage standpoint but also for computing “group by” queries since you have already bucketed the events by value; this can turn a hashmap lookup into an array lookup, which is a huge difference for CPU-bound computations. The columnar data format is typical of any such database, and we apply the generic ) on top of individual columns when the data is large enough.
Building on existing work
One of the main challenges with building an in-house column store is developing it in a way that has both the reliability and performance of other solutions. We are fortunate to build upon the services of AWS and the work of many before us who have figured out best practices. There are a handful of systems that we drew inspiration from during the design and development of Nova:
- is an analytical column store built by Google that uses a highly-optimized storage format to process billions of rows interactively;
- Facebook built a performance monitoring system called that has a hierarchical aggregation model on top of an in-memory storage layer;
- is a columnar database designed by Microsoft to allow flexible queries that still compile to performant data processing code; and
- Metamarkets’ , the open-source column store we described earlier, uses lambda architecture to ensure long-term data integrity.
While we did go down the path of building our own system, we were able to leverage and combine several of the ideas behind these technologies. The resources provided were invaluable to us when making difficult design decisions (of which there were many!). [Tweet “Pushing the boundaries of behavioral #analytics with Nova architecture”]
The future of scalable analytics
Analytics is all about the performance versus cost trade-off, and Nova is designed from the ground up to achieve the best of both worlds. Today, we process over 70 billion events per month and regularly serve queries that scan 10-20 billion events; overall, 95% of queries take less than 3 seconds, which allows for powerful interactive analysis. In the future we will be processing and querying orders of magnitude more than we do now, and we expect Nova to take us there. Many systems exist that offer the capability of handling data at large volumes by throwing money at the problem and adding more machines, but for us what matters is being able to do this cost-efficiently . Scalability aside, a column store is a very flexible foundation on which to build new features, and owning the architecture empowers us to develop advanced functionality that a SQL-based system can never achieve. We are excited to use the technology we have developed to push the boundary of behavioral analytics.
Comments
Michael: It seems that the event data is stored in your database that uses columnar-storage format but how do you store user data? The user attribute data is not immutable and complex operations such as setOnce, incrementBy, add is supported by Amplitude. Also querying over user data-set is different from event data-set because the queries are simply lookup for a specific user. (search by user attribute, get user attributes, or timeline etc.)
Jeffrey Wang: Hi Michael, great question. You’re right to observe that the user data is both mutable and queried in a very different way from the event data. We store user information in DynamoDB and fully denormalize it at data collection time, attaching user properties to all events as they come in.
Ali: It seems that you completely abandoned pre-aggregation in favor of your in-house optimized columnar database. Did you consider using ORC or Parquet as storage format, they’re also highly optimized and used in production by big companies such as Facebook and Twitter. There’s also TrailDB from Adroll which makes efficient to analyze individual user timeline and designed specifically for behavioral analytics. Is there any difference between the storage format used in Nova and these technologies?
Jeffrey Wang: TrailDB is an interesting technology that we haven’t looked into before. Seems like it’s a strong candidate for a more structured use case, but the lack of Java support would be a deal-breaker for us.
M Lemoine: Very interesting article. It’s a difficult decision to decide to build an in-house database technology. How much time and people were required to build the first version of this database? Have you any plans to open-source this technology in the future?
Jeffrey Wang: As for open-sourcing, we think it’d be really cool to get there; however, in order to get things out the door faster we don’t spend much time thinking about how Nova might generalize to other datasets and queries. It’d take a significant effort to put in the right layer of abstraction to make it worth open-sourcing, but only time will tell 🙂