Can Agents Take On Enterprise Analytics?
A task-based evaluation of AI analytics agents


This post was co-authored by Jacob Newman, Principal AI Product Manager at Amplitude.
Table of contents
Every vendor claims their analytics platform is “AI-powered.” But there’s a massive gap between auto-generated chart captions and intelligent systems that investigate your data, diagnose root causes, and recommend what to do next. Without clear benchmarks, buyers can’t separate real capability from noise.
We introduce a task-based evaluation for assessing AI analytics agents across four foundational question types: descriptive, diagnostic, predictive, and prescriptive.
Amplitude’s Global Agent achieves an overall score of 76% across all four tasks, which is a 7x+ improvement over six months of building and iterating. It excels at descriptive and diagnostic analytics with emerging capabilities in predictive and prescriptive analytics.
Figure 1. Global Agent’s overall success across all analytics tasks, showing consistent improvement over time. The baseline of 9% represents best-in-class warehouse Text-to-SQL performance on multi-query production-grade workflows.
By publishing our framework and scores, we establish a shared language for the industry, help teams evaluate solutions rigorously, and elevate customer expectations for what an AI analytics agent must do.
Key takeaways
- AI analytics agents should be evaluated on their ability to do real-world analytics tasks effectively.
- Best-in-class AI analytics agents must succeed across four analytics tasks: descriptive, diagnostic, predictive, and prescriptive.
- Amplitude’s Global Agent excels at descriptive and diagnostic tasks, with emerging strength in predictive and prescriptive ones.
- Descriptive analytics: 80%
- Diagnostic analytics: 76%
- Predictive analytics: 63%
- Prescriptive analytics: 50%
Defining AI analytics agents
AI analytics agents use statistical analysis and large language models to automatically surface insights from behavioral and business data. These agents are designed to interpret natural-language questions, query relevant data, apply the right analytical workflows, and reliably explain results and next steps.
A mature AI analytics agent will deliver true, meaningful insights to end users. We define an “insight” as a single data-driven observation that deepens understanding of users, products, campaigns, or processes and enables better decision making.
Eight-step agent workflow for responding to analytics tasks
Strong AI analytics agents should follow these eight steps when doing analytics tasks.
|
Step |
Description |
|
1. Understand natural language questions |
Correctly interprets user intent and analytical goals from plain language (including ambiguous or multi-part questions) and routes them to the appropriate analysis type |
|
2. Query the correct data sources and taxonomy |
Selects the correct data sources, event schemas, and metric definitions for a given question, and flags ambiguity or gaps |
|
3. Build the correct analytical workflow |
Automatically applies the right chart type, time grain, segments, statistical tests, and transformations without requiring manual setup or intervention |
|
4. Perform analytics subroutines |
Systematically investigates relevant factors across segments, time, features, campaigns, and instrumentation to identify and compare plausible root causes |
|
5. Use real-world, domain-aware context |
Interprets patterns using relevant business and product context, such as seasonality, releases, campaigns, or industry trends, when appropriate |
|
6. Surface meaningful, actionable insights |
Moves beyond description to explain significance, propose hypotheses, and highlight implications, while clearly communicating confidence and uncertainty levels |
|
7. Present results transparently and reliably |
Clearly shows inputs, reasoning, and evidence by linking claims to charts, tables, and sources; avoids unsupported claims and hallucinations |
|
8. Support prescriptive action and iteration |
Translates insights into concrete, context-aware next steps and supports natural follow-up without restating context across multi-step workflows. |
AI analytics tasks
A strong AI analytics agent must handle a wide spectrum of questions, from basic “What happened?” questions to sophisticated “Why did it happen?” and “What should we do?” investigations.
We define four key tasks reflecting the types of analytics questions an agent should be able to answer:
- Descriptive analytics: What happened?
- Diagnostic analytics: Why did it happen?
- Predictive analytics: What will happen?
- Prescriptive analytics: What should we do?
Figure 2. The four AI analytics tasks by task complexity
These tasks define the distinct categories of manual analytics work that AI agents should reduce, in order of increasing complexity. An agent that only answers descriptive questions still forces teams to manually investigate causes, evaluate impact, and determine next steps, shifting the hardest analytical work back to users.
For each task, we define representative questions in business language and the characteristics of a good AI answer. This grounds the framework in how real analysts work while remaining intuitive for product, marketing, and data leaders evaluating AI analytics platforms.
Descriptive analytics task
At a minimum, an AI analytics agent should be able to answer “What happened?” by describing user behavior and business performance across metrics, time periods, and segments. This task determines whether an agent can extract insights from data and convey them in plain language.
|
Descriptive analytics |
|
|
Representative questions |
|
|
What a good AI answer looks like |
|
This task validates whether an AI analytics agent understands the underlying data, taxonomy, and metric definitions, and can translate natural language questions into accurate analyses. If an agent struggles with descriptive analytics, it does not yet have a robust system.
Diagnostic analytics task
An AI analytics agent should also be able to answer “Why did this happen?” by doing multi-step analysis, exploring multiple hypotheses, and identifying plausible root causes. This task evaluates whether an agent can move beyond description to provide explanation, without requiring users to manually investigate.
|
Diagnostic analytics |
|
|
Representative questions |
|
|
What a good AI answer looks like |
|
This task validates whether an AI analytics agent can systematically investigate causes, rule out false signals, and return evidence-backed root causes. If the agent can describe what happened but not explain why, it is not true AI analysis.
Predictive analytics task
An AI analytics agent should be able to answer “What will happen?” by forecasting future outcomes based on historical patterns, behavioral signals, and current trends. This task evaluates whether an agent can generate credible predictions grounded in data rather than speculation.
|
Predictive analytics |
|
|
Representative questions |
|
|
What a good AI answer looks like |
|
True predictive capability is more than a churn score. An AI analytics agent should anticipate future outcomes, communicate prediction drivers, provide confidence ranges, and adapt as conditions change.
Prescriptive analytics task
At the highest level of maturity, an AI analytics agent should be able to answer “What should we do?” by recommending actions informed by descriptive, diagnostic, and predictive insights. This task evaluates whether an agent can translate analysis into actionable next steps.
|
Prescriptive analytics |
|
|
Representative questions |
|
|
What a good AI answer looks like |
|
Prescriptive analytics capabilities guide decision making and help teams determine next steps by tying recommendations directly to historical user behavior and predicted outcomes. Look for AI analytics agents that can propose data-backed actions, articulate expected impact, and communicate potential risks or tradeoffs.
Evaluating Amplitude’s Global Agent on AI analytics tasks
To set an industry baseline, we scored Amplitude’s Global Agent on all four tasks by asking representative questions across real analytics workflows. We evaluated each response using an LLM-as-a-judge approach against human-defined criteria. The scores represent the percent of responses that successfully captured the desired insight.
Figure 3. Global Agent’s success by task, highlighting its strength in descriptive and diagnostic analytics tasks, with emerging capabilities in predictive and prescriptive tasks
Overall, we would expect most AI analytics agents to do reasonably well at descriptive analytics tasks, with sharp drop-offs for diagnostic ones. Global Agent demonstrates strength in both, reliably explaining what happened and why through consistent diagnostic reasoning. Other AI analytics agents are unable to meet this diagnostic bar, let alone provide predictive or prescriptive offerings. Global Agent shows emerging capabilities in both areas.
Score summary
|
Analytics task |
Description |
Evaluation example |
Amplitude score |
|
Descriptive |
Accurately describes what happened across users, products, and revenue using consistent metrics and business logic. |
How many users clicked the “Upgrade” button last week, and how does that compare to the prior period? |
80% |
|
Diagnostic |
Explains why changes occurred by investigating multiple drivers, segments, and potential data issues. |
Why did the conversion from free trial to paid upgrade decline after the latest release? |
76% |
|
Predictive |
Anticipates what will happen next using historical patterns and behavioral signals. |
Which users are most likely to upgrade in the next 30 days? What behavior best predicts that conversion? |
63% |
|
Prescriptive |
Recommends actions tied to underlying analysis, expected impact, and tradeoffs. |
What actions would most improve upgrade conversion among at-risk users? |
50% |
Descriptive analytics score
Score: 80%
Global Agent scores highest in descriptive analytics. The agent reliably answers “What happened?” across user behavior, product usage, and revenue growth. This includes accurately selecting metrics and taxonomy, applying time ranges and comparisons, and running the correct analyses.
Global Agent reduces manual analytical work by ensuring descriptive questions are answered clearly and accurately without requiring users to configure charts.
Diagnostic analytics score
Score: 76%
Global Agent scores highly at the diagnostic level. The agent can investigate why changes occur by exploring multiple hypotheses and returning evidence-backed root cause explanations.
This task reflects Global Agent’s strength in multi-step, multi-dimensional analysis and behavioral reasoning. This is an area where many AI analytics tools still rely on manual investigation or surface-level explanations.
Predictive analytics score
Score: 63%
Global Agent’s advanced predictive capabilities are continuing to evolve. The agent can anticipate future outcomes for select scenarios in a way that many AI analytics tools or manual analyses cannot. But predictive analytics remains an area of active investment and refinement.
For this task, our focus is on building forecasts that are credible, grounded in meaningful signals, and transparent about uncertainty.
Prescriptive analytics score
Score: 50%
Prescriptive analytics represents the frontier of AI analytics. Global Agent can propose data-backed next steps in many contexts, and even take some actions itself. But we do not treat our prescriptive capability as “solved.”
Our approach emphasizes improved decision making and action by tying recommendations back to observed behavior, expected impact, and tradeoffs. This task reflects where the industry is heading and where Amplitude is actively building.
AI analytics evaluation in practice
This evaluation defines what “good” looks like across descriptive, diagnostic, predictive, and prescriptive analytics tasks. To make this concrete, we provide example questions and Global Agent’s responses below.
Together, these examples illustrate how AI analytics agents should be evaluated and what a high-scoring AI-generated insight looks like.
Evaluations: Example questions and high-scoring responses
The table below presents a set of representative questions spanning user behavior, product usage, funnel conversion, and marketing performance, and Global Agent’s response to those questions.
For clarity, we’ve summarized Global Agent’s non-deterministic responses in the table, with the full analyses and charts linked throughout.
|
Analytics question |
Global Agent response summary |
|
How many users drop off during onboarding? |
The biggest drop-off happens between the onboarding flow and account creation—88.6% of users who engage with onboarding don’t complete sign-up. |
|
What’s the conversion rate for adding an item to the cart to checkout in the US? |
The conversion rate from adding an item to the cart to checkout for US users is 39.5% over the last 30 days. This means about 4 in 10 US shoppers who add items to their cart proceed to checkout. |
|
How many visitors did our landing page get in November? |
Your landing page received 220,570 unique visitors in November 2025. November 26th had the largest single-day traffic, with 19,454 visitors. |
|
Break down our landing page visitors by traffic source. |
Traffic source distribution: 1. Google - 122,460 visitors (36%) 2. Instagram - 92,907 visitors (27%) 3. Direct - 87,231 visitors (26%) 4. Facebook - 84,935 visitors (25%) 5. Twitter - 25,941 visitors (8%) 6. Bing - 7,205 visitors (2%) |
|
Which marketing campaigns are bringing in the highest-value customers? |
Paid Search is bringing in the highest-value customers, with a Revenue Per User (RPU) of $170.12 and an Average Order Value of $109.92—significantly outperforming other channels. |
|
What’s our weekly active user trend and retention over the last 90 days? |
Your weekly active users have been relatively stable around 115k-140k over the last 90 days, with peaks in late October and early December, followed by a mid-December dip—likely reflecting seasonal patterns or holiday behavior. |
|
How do mobile vs. web users differ in purchase behavior? |
Web users drive the most purchases, with 2.4k–2.9k daily unique purchasers compared to iOS (1.4k–1.7k) and Android (~1.2k–1.5k). All platforms show consistent weekend dips, suggesting similar shopping patterns across devices. |
|
Which platform has the highest average order value? |
All three platforms have nearly identical average order values at ~$80–$83 per purchase, with remarkable consistency over the past 90 days. iOS shows occasional spikes slightly above Web and Android, but the differences are minimal.
|
Anatomy of a high-scoring AI insight
While the evaluation cases show what questions an AI analytics agent should be able to answer, the visual below illustrates what a strong AI-generated response should look like.
We break down a single Global Agent example, from question to output to follow up, and highlight the essential components that distinguish a “gold-standard” insight from a surface-level response. The fully annotated diagram is available here.
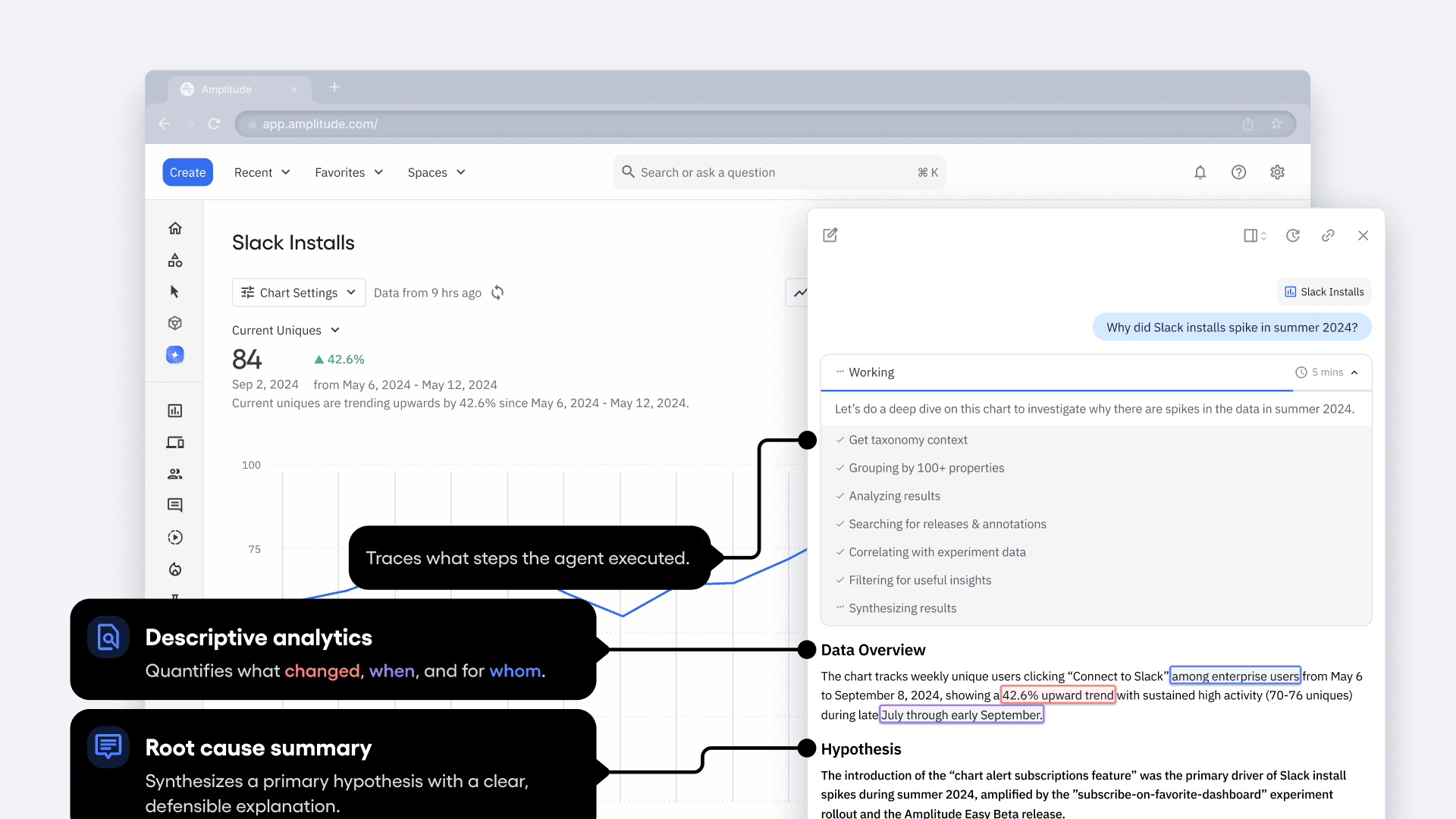
Figure 4. Preview of Global Agent’s response
Setting the standard for best-in-class AI analytics agents
As product and marketing data grow more complex, the value of AI analytics agents comes from the ability to reduce manual analytical work, surface meaningful insights, and support better decision making and action throughout the business.
This evaluation offers a clear, task-based framework to assess whether an AI analytics agent meets that bar by defining what “good” looks like across analytics tasks.
Using this framework to evaluate Amplitude’s Global Agent highlights our ability to reliably answer what happened and why through accurate data interpretation, multi-step reasoning, and evidence-backed explanations. The evaluation also surfaces Global Agent’s emerging capabilities in predictive and prescriptive analytics, where we are actively building today.
For buyers navigating a crowded market, this evaluation offers a practical framework to guide your decision and a clear example of what a mature AI analytics agent should be able to do. Amplitude best-in-class AI analytics platform delivers analytical rigor and enables teams to move faster and act on insights with confidence.
As AI analytics continues to evolve, the gap between surface-level automation and true analytical intelligence will only widen. We are committed to leading the category forward and invite people to share their thoughts with us on X.
Learn more about how Amplitude AI Agents are changing the way teams build products in our webinar.
Acknowledgements
This evaluation is the result of close cross-functional collaboration and domain expertise from engineering, product, and design. Thank you to the following individuals for their contributions: Adam Lohner, Adam Struck, Amogh Dikshit, Andrew Chou, Ashkan Aghdai, Avery Chan, Ben Feigin, Brian Cooper, Brian Giori, Chamila Amithirigala, Chris Yu, Eric Carlson, Eric Kim, Frank Lee, Henry Arbolaez, Jacob Newman, Jake McKibben, James Evans, Janaki Vivrekar, Jin Wan, Jingshu Zhao, Jimmy Wilson, Karan Johar, Kevin Wu, Larry Xu, Marvin Liu, Nhi Dao, Nirmal Utwani, Peyton Rose, Pranjal Joshi, Ram Soma, Richard Fang, Ryan Busk, Shawn McKay, Skylar Givens, Steven Cheng, Tommy Keeley, Tyler Wanlass, Vinay Ayyala, Vinay Goel, Will Newton

Janaki Vivrekar
Software Engineer, Amplitude
Janaki Vivrekar is a Software Engineer at Amplitude where she builds tools for Amplitude users to collaborate and share insights. She is a UC Berkeley graduate with degrees in Computer Science, Applied Math, and Human-Computer Interaction, with a background in new media and education. When not at work, Janaki enjoys inventing vegan recipes and hand-drawing mandala art!
More from JanakiRecommended Reading

How Cisco Systems Accelerated Adoption by 20% Through Data Innovation
Apr 15, 2026
5 min read

What 27,000 AI Sessions Taught Us About How People Use Agents
Apr 15, 2026
12 min read

Creating the Intelligence Layer: Welcoming CPO Gab Menachem
Apr 14, 2026
6 min read

How We Built Agents That Understand The Language of Product Analytics
Apr 13, 2026
20 min read