Why We Created Agent Analytics, and Why Every Team Building AI Agents Needs It
We built an analytics company. Then we built an agent and couldn't see anything. Here’s how we solved it.

This blog post was co-authored by Jacob Newman, Principal AI PM and Nikhil Gangaraju, PMM lead at Amplitude
Amplitude is a product analytics company. We've spent more than a decade helping product teams understand what their users are doing and why. Funnels, retention curves and behavioral cohorts. We know this stuff. And yet, when we started building our own AI agent last year, we found ourselves in a weird spot:
We had no idea if our agent was actually good.
Not “good” in the way we'd normally measure a product. We had engagement metrics and activation rates and NPS scores. But none of them told us the thing we actually needed to know: When a user asked our agent a question, did it give them a useful answer? When it failed, why? Was it a bad prompt? Missing context? A broken tool call? If users had a bad experience, did they churn? If they had a great one, did they retain better or upgrade?
Up until now, we’ve built our careers on the idea that great products come from understanding user behavior. But the moment our “product” became a non-deterministic AI agent, our entire observability stack became irrelevant.
Why traditional product analytics failed us
Our existing analytics still worked for what they were designed to do. We could see how many people opened the agent. We could track session length, feature adoption, retention. The dashboards were green. The charts went up and to the right.
But a user can open an agent, have a two-minute conversation, and leave furious. That shows up in traditional analytics as an engaged session. Two minutes! Multiple events fired! The funnel says “activated.” In reality, the user asked a question, the agent hallucinated, and the user decided our product was broken.
Traditional product analytics was built for a world where users click buttons and navigate pages, where the product’s behavior is deterministic and you can infer intent from actions. Agents flip that.
With an agent, the user states their intent explicitly (they literally type what they want), but the product's behavior is unpredictable. The agent might call the right tools in the right order and nail the answer. Or it might misinterpret the request, call the wrong tool, hallucinate a data point, and confidently present garbage as insight. Both paths generate events. Both look identical in a traditional analytics dashboard.
We started to realize our blind spots were everywhere.
- We couldn't measure quality. Was the agent's output accurate? Did it answer what the user asked? Traditional analytics tracks that something happened, not whether the experience was good. For non-deterministic products that generate free-form responses, that distinction was a big shift.
- We couldn't debug failures either. When something went wrong (and with agents, things go wrong in creative ways), we had no systematic way to understand the chain of reasoning that led there. Was the system prompt too vague? Did retrieval return irrelevant context? Did the model hallucinate despite having the right information? Each failure mode requires a completely different fix.
- Experimentation was a mess. In traditional product development, you A/B test a feature release or a flow change and measure the outcome. With agents, the variables are prompt wording, context window composition, tool selection logic, model temperature. The outcomes are qualitative: Did the response make sense? Was it helpful? Did the user trust it? Our experimentation framework wasn't built for any of this.
- And we couldn't measure ROI. The team was asking the right questions: “Do great agent interactions encourage free users to upgrade?” “When our agents hallucinate, what does it cost us?” But with no quality signals beyond shallow engagement data, nobody could answer them.
The irony was hard to miss. A decade of telling customers you can’t build great products without great analytics, and now we were building an agent with essentially no signal into whether it was working.
We talked to other teams building agents. The pattern was universal. Everyone was cobbling together logging frameworks, LLM observability tools, and some vibes. The observability tools gave us traces so you could see what the model did step by step, but these traces operated at the infrastructure level. They told you how the model was running, not whether the product was succeeding. On the flip side traditional analytics tools told us about user behavior around the agent but couldn't see inside the conversation.
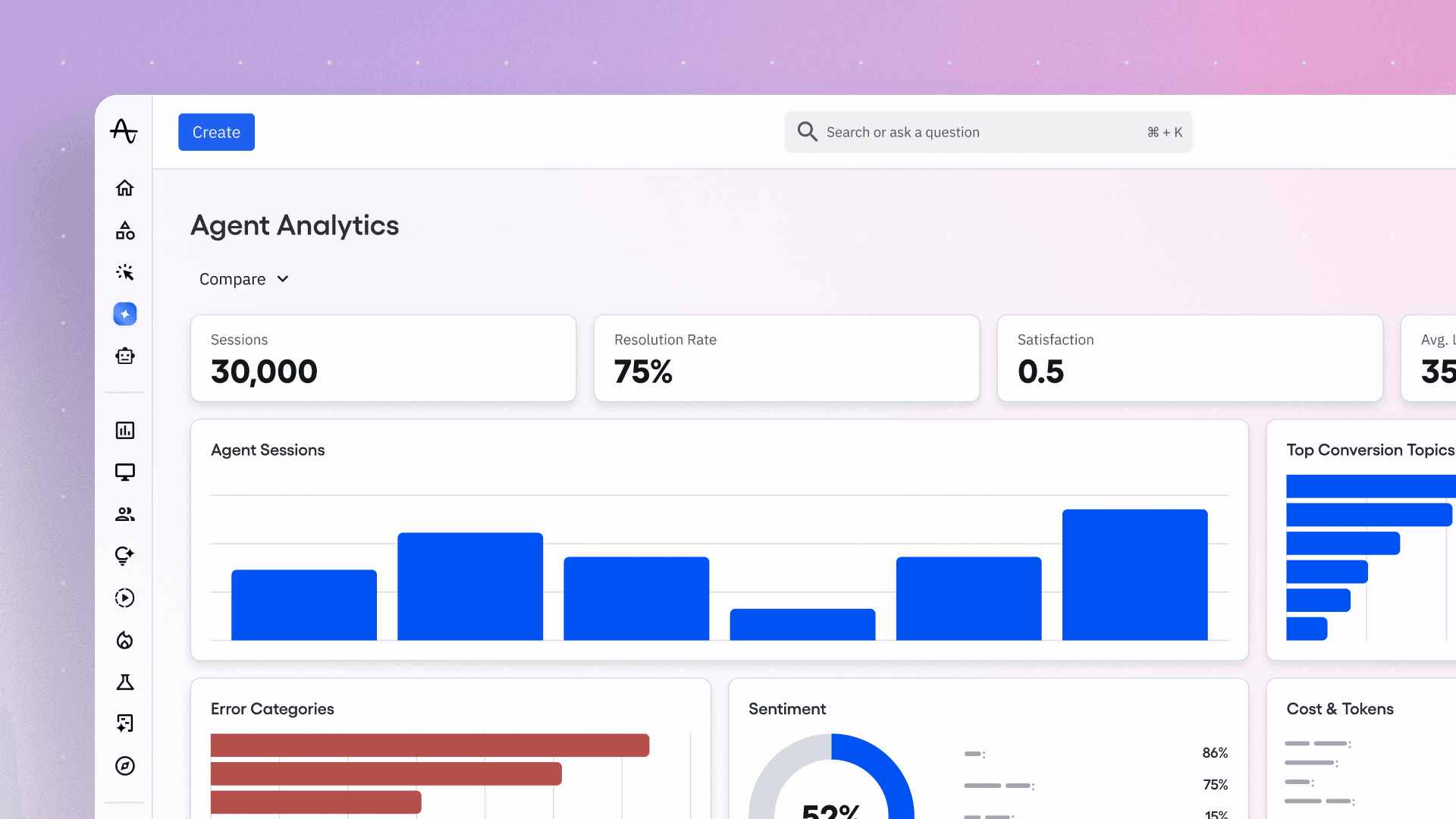
Nobody had the full picture. So we built Agent Analytics.
What is Agent Analytics?
Agent Analytics sits between product analytics and LLM observability. It’s not a logging tool. It’s also not a dashboarding layer on top of LLM traces. It’s a system for understanding how your AI agent performs as a product, from the user’s perspective, with enough depth to actually diagnose and improve it.
When building Agent Analytics, we didn’t set out to replace the deep technical traces engineers use to monitor infrastructure. Instead, it acts as a bridge to take those technical signals and translate them into the language of the product like user retention, conversion, and intent.
A trace is the full record of a conversation between a user and your agent: a multi-turn interaction with intent, reasoning, tool usage, and an outcome that can be evaluated. Unlike observability tools that stop at the trace, Agent Analytics decomposes these conversations into events, directly queryable in the same funnels, cohorts, and retention analyses you already use for everything else.
When you treat traces as the primary object for your analytics, a few things start to open up:
You can see what your users are actually trying to do. Agent analytics clusters user queries by intent, surfacing the most common requests, and shows you where your agent consistently delivers versus where it falls apart. This is the product-market fit signal that traditional analytics can't give you. You're no longer guessing from behavior patterns. Instead users inside your agent are telling you.
You can trace failures to the root cause. When the agent fails, you drill into the full trace: what the user asked, how the agent interpreted it, which tools it called, what context was retrieved, where things went sideways. Prompt issue? Tool issue? Context issue? This is what makes the Agent Analytics system actionable.
You can measure quality at scale. Every trace gets evaluated automatically via configurable evals to determine whether the agent succeeded, partially succeeded, or failed. You can track quality over time, across user segments, across query types. When you deploy a new prompt or add a new tool, you see whether quality went up or down in production, continuously.
Experiment on what drives agent behavior
Instead of A/B testing surface-level UI changes, you can experiment on the inputs that drive agent behavior: prompt variations, tool configurations, context strategies, model parameters.
We’re already seeing this play out with autonomous experiment loops in which AI agents run hundreds of prompt variations overnight and pick the best performers. Shopify’s sidekick team for example built an LLM-powered simulator to run candidate systems overnight and select the winner.
But those systems primarily optimize for model quality metrics like validation loss. They have no way to know whether the winning variant actually improved retention or conversion for real users. With Agent Analytics, you can measure the impact on interaction quality and downstream business outcomes.
How Agent Analytics became our foundation for online evals
After we shipped Global Agent with a 76% pass rate on our offline eval set, we quickly hit a wall. Offline evals had been essential for optimizing against realistic questions, but they’d saturated. They couldn’t capture the full diversity of how customers actually use the agent in practice. What we really needed was high-fidelity observability into real conversations, with real data, at scale.
Agent Analytics gave us that lens. We started to surface conversations with negative signals—thumbs-down reactions, abandoned threads, tool errors. We manually reviewed them, tagging each with specific error codes and building a failure taxonomy grounded in what we actually observed. Once the taxonomy was stable, we deployed automated classification to monitor for regressions and track top error categories continuously.
Creating this foundation led to real improvements: 80% thumbs-up rate, 90% positive signal rate, and dozens of verified customer impact signals where specific fixes led to measurably better outcomes for our agent. Building Agent Analytics forced us to solve the exact measurement problem that every team building an agent at scale was facing.
We had effectively developed the components of a new kind of analytics system. Eval rubrics became quality scorers. Our session explorer became the trace viewer. Our LLM judge became our enrichment pipeline.
Agent analytics came out of the unglamorous work of trying to make our own agent better, and discovering that no existing tool gave us what we needed.
How Agent Analytics connects to business outcomes
The question every team building agent eventually asks: Which interactions drive our key metrics? Is the agent improving long-term retention? What about revenue? Which behaviors cause churn?
Answering this question can actually shift AI from cost center to revenue line item. Neither model providers (they don’t have downstream user data) nor observability tools (they don’t have product analytics) can get here on their own. In some ways, it looks like attribution modeling for agents.
Existing observability tools focus on the trace itself. But what was the user doing five minutes before they opened your agent? What did they do two minutes after? Two days after? Did a successful interaction lead to feature adoption, an upgrade, a referral? Did a failure correlate with churn 30 days later?
Inside Agent Analytics, AI session data and product event data share the same user identity. These questions stop being data engineering projects. For example, we found internally that Amplitude users who had high-quality agent sessions retained at 2.3x the rate of users who hit task failures.
Let’s take a hypothetical example of an agent that handles both product recommendations and returns. Recommendation sessions convert to purchase at 35%. Return sessions however convert at 2% and cost 3.5x more to run, because the agent keeps asking for the same information, triggering retries, and dragging out conversations until the user quits. In this scenario, you’re spending the most on the thing that’s failing the most.
Agent Analytics shows you both gaps (quality and cost) in one place. So instead of “our AI costs X per month,” you’re asking, “Why are we spending 3.5x more per session on the topic with the worst outcomes?”
Content-optional analytics
The number one concern we heard from privacy-sensitive customers early on: “We can't send you prompt content.”
You don‘t need content to get value. But you need it for the full value.
We’ve built privacy tiers that work as an adoption onramp. Even at the metadata-only tier, you get cost analytics, retention segmentation, and behavioral signals like regeneration rate and abandonment.
What you lose without content is the enrichment layer: the automatic “your returns agent is failing on refund requests for enterprise users” that surfaces without anyone building a dashboard.
In closing
We built Agent Analytics because we had to. We were building an agent and we couldn’t see whether it was working. The existing tools gave us pieces of the picture, infrastructure metrics over here, engagement numbers over there, but nobody was stitching together the full story from the user’s perspective.
What we found the most valuable was going from a failure to acting on it. When we see a specific group of users hitting a “hallucination loop,” we didn't just log it; we used that data to immediately test a fix or guide those specific users toward a better outcome.
If you’re building an agent right now, you’re probably feeling the same thing. You ship a new version, update the system prompt, add new tools, and you don’t really know if it’s better. Your team might be reviewing traces by hand because there’s no automated way to measure quality. When something goes wrong, you’re digging through scattered logs trying to reconstruct what happened. You want to experiment with prompts or tools, but you don’t have a rigorous way to measure the impact.
That’s where we were six months ago.
If any of this resonated and you’re ready to get started, we’d love to work with you. Sign up here to join our Partner Design Program for early access.

Vinay Goel
Staff AI Engineer, Amplitude
Vinay is a Staff AI Engineer at Amplitude. He builds the foundational AI platforms that empower internal innovation and help define the future of AI-driven analytics at scale.
More from VinayRecommended Reading

Making AI Search Count (and Convert)
Apr 29, 2026
4 min read

How VEED Evolved Its AI Search Strategy
Apr 29, 2026
3 min read

What’s New with Amplitude Agents
Apr 28, 2026
4 min read

Effortless Support at Scale: Making Human Support More Human
Apr 28, 2026
11 min read